





Test karty graficznej NVIDIA GeForce RTX 2080 SUPER - Premiera
- SPIS TREŚCI -
- 1 - Jeszcze jeden Turing w wersji SUPER
- 2 - NVIDIA Turing - trochę więcej o architekturze
- 3 - NVIDIA GeForce RTX 2080 SUPER - Budowa i parametry techniczne
- 4 - Platforma testowa i wykorzystane sterowniki
- 5 - Test wydajności RTX 2080 SUPER - 3DMark Time Spy
- 6 - Test wydajności RTX 2080 SUPER - Assassin's Creed: Odyssey
- 7 - Test wydajności RTX 2080 SUPER - Battlefield V
- 8 - Test wydajności RTX 2080 SUPER - Hitman 2
- 9 - Test wydajności RTX 2080 SUPER - Kingdom Come: Deliverance
- 10 - Test wydajności RTX 2080 SUPER - Metro Exodus
- 11 - Test wydajności RTX 2080 SUPER - Shadow of the Tomb Raider
- 12 - Test wydajności RTX 2080 SUPER - Witcher 3: Wild Hunt
- 13 - Test wydajności RTX 2080 SUPER - Wolfenstein II: The New Colossus
- 14 - Overclocking - maksymalne stabilne zegary
- 15 - Test wydajności RTX 2080 SUPER - 3DMark Time Spy (OC)
- 16 - Test wydajności RTX 2080 SUPER - Battlefield V (OC)
- 17 - Test wydajności RTX 2080 SUPER - Witcher 3: Wild Hunt (OC)
- 18 - Test wydajności RTX 2080 SUPER - Wolfenstein II: The New Colossus (OC)
- 19 - Test wydajności RTX 2080 SUPER - Battlefield V (DXR i DLSS)
- 20 - Test wydajności RTX 2080 SUPER - Metro: Exodus (DXR i DLSS)
- 21 - Test wydajności RTX 2080 SUPER - Shadow of the Tomb Raider (DXR i DLSS)
- 22 - Pobór mocy - Spoczynek i obciążenie (Battlefield V)
- 23 - Pomiar temperatur - Spoczynek i obciążenie (Wiedźmin 3)
- 24 - Pomiar głośności - Spoczynek i obciążenie (Wiedźmin 3)
- 25 - Podsumowanie - Do trzech razy sztuka?
NVIDIA Turing - trochę więcej o architekturze
Rdzenie Turing stworzono przy wykorzystaniu 12 nm litografii FFN (FinFET NVIDIA), będącej usprawnioną odmianą 16 nm procesu technologicznego dedykowanego układom graficznym NVIDII, bowiem 7 nm odpowiedniej sprawności jeszcze nie osiągnęło (zwłaszcza przy ogromnych GPU). Układ TU102 (GeForce RTTX 2080 Ti) mierzy 754 mm² zawierając 18.6 miliarda tranzystorów, TU104 (GeForce RTX 2080 / RTX 2080 SUPER / RTX 2070 SUPER) mierzy 545 mm² skrywając 13.6 miliarda tranzystorów, natomiast TU106 (GeForce RTX 2070 / RTX 2060 SUPER) mierzy 445 mm² przy 10.8 miliarda tranzystorów. Szczegółowe dane techniczne zamieszczam w tabelkach, znajdziecie tam również taktowania poszczególnych procesorów graficznych, jednak tym razem Founders Edition nie oznacza wersji referencyjnej - NVIDIA podniosła swoim kartom częstotliwości GPU Boost, a dodatkowo wprowadziła wydajniejsze chłodzenie z dwoma wentylatorami, stwarzając konkurencję dla producentów AiB.
![NVIDIA GeForce RTX 2070, 2080 i 2080 Ti - Architektura i specyfikacja [2]](https://www.purepc.pl/image/mini_recenzja/2018/09/12_nvidia_geforce_rtx_2070_2080_i_2080_ti_architektura_i_specyfikacja_1_b.png)
![NVIDIA GeForce RTX 2070, 2080 i 2080 Ti - Architektura i specyfikacja [20]](https://www.purepc.pl/image/mini_recenzja/2018/09/12_nvidia_geforce_rtx_2070_2080_i_2080_ti_architektura_i_specyfikacja_19_b.png)
NVIDIA przedstawia architekturę Turing w kategorii największego skoku jakościowego w rozwoju układów graficznych ostatniego dziesięciolecia, czyli momentu wprowadzenia rodziny GeForce 8000 oraz zunifikowanych shaderów, które przejęły funkcje vertex i pixel shaderów, wykonując również inne obliczenia np.: fizyki obiektów czy geometrii. Cofamy się zatem do absolutnych początków DirectX 10 oraz implementacji w rdzeniach graficznych skalarnych jednostek zmiennoprzecinkowych zamiast tradycyjnych wówczas wektorowych. Turing to architektura stworzona do renderowania hybrydowego, gdzie wykorzystywany będzie ray tracing w czasie rzeczywistym oraz tradycyjna rasteryzacja, a dodatkowo sztuczna inteligencja oraz wianuszek innych autorskich rozwiązań, które wspólnie mają podnieść poziom realizmu oprawy graficznej. Jak producent to osiągnął? Ciekawych pomysłów jest naprawdę niemało, a znajdziemy tutaj chociażby nowe jednostki obliczeniowe dedykowane konkretnym zastosowaniom. Poniżej opisuję najważniejsze elementy Turinga, aczkolwiek NVIDIA wysmarowała ponad 80-cio stronicowy dokument opisujący wszystkie szczegóły techniczne (tzw. whitepaper), którego streszczenie zajęłoby przynajmniej połowę niniejszego artykułu. Wybaczcie więc wybiórczość.
Turing dziedziczy wszystkie ulepszenia rdzeni CUDA wprowadzone w architekturze Volta, zawierając także wachlarz zaawansowanych funkcji cieniowania, które poprawiają wydajność, jakość obrazu i złożoność geometryczną trójwymiarowych scen. Konstrukcja chipu przeszła gruntowną przemianę względem poprzedników (Pascala), zbliżając się do architektury Volta. Strukturę SM podzielono na cztery bloki przetwarzania, każdy zawierający 16 rdzeni FP32 i INT32, dwa rdzenie Tensor, pojedynczy układ planowania oraz wysyłania wątków. Osobno dostawiono po jednym rdzeniu RT. Sumarycznie dla każdego pełnego SM oznacza to dokładnie 64 procesory CUDA, 8 jednostek Tensor, 4 jednostki TMU oraz pojedynczą jednostkę RT, toteż GeForce RTX 2080 Ti bazujący na układzie dysponującym 68 SM, posiada 4352 jednostki cieniujące, 544 jednostki Tensor, 272 jednostki TMU oraz 68 rdzeni RT. W przypadku Pascala na każdy SM przypadało 128 procesorów CUDA oraz 8 jednostek TMU, natomiast rdzenie Tensor i RT nie występowały wcale. Turing otrzymał także nowy mechanizm zrządzania pamięcią L1 Cache działającej przy niższych opóźnieniach oraz dwukrotnie większy L2 Cache.
![NVIDIA GeForce RTX 2070, 2080 i 2080 Ti - Architektura i specyfikacja [3]](https://www.purepc.pl/image/mini_recenzja/2018/09/12_nvidia_geforce_rtx_2070_2080_i_2080_ti_architektura_i_specyfikacja_2_b.png)
Pełny blok SM Turing
Warto również zaznaczyć, że najmocniejsze odmiany układów graficznych Turing TU102 trafiły do akceleratorów montowanych w stacjach roboczych, bowiem GeForce RTX 2080 Ti wykorzystuje 68 SM, podczas gdy NVIDIA Quadro RTX 6000 otrzymało 72 SM, dopełnione 384-bitową magistralą pamięci GDDR6. Łatwo zatem wykalkulować, że gdyby NVIDIA naprawdę potrzebowała wydać mocniejszą kartą graficzną, dysponuje jeszcze całkiem sporym zapasem, który prawdopodobnie wykorzysta w kolejnej generacji RTX-ów albo stworzy na poczekaniu nowego Titana. Teoretycznie Zieloni mogliby przygotować potworka mającego nawet 80 SM, podobnie jak Quadro GV100 bądź Titan V, posiadających 5120 CUDA, 320 TMU, 128 ROP, 640 Tensor i 80 RT. Trudno zatem oprzeć się wrażeniu, że rodzina GeForce RTX będzie niebawem poszerzona o kolejne high-ednowe modele, zwłaszcza gdy deweloperzy podkreślają jak bardzo zasobożerna jest technika ray tracingu. Jedynym ograniczeniem może okazać się zdolność wytwarzania takich gigantycznych rdzeni na masową skalę w fabrykach TSMC, bowiem mierzyłyby ponad 800 mm². No dobrze, przejdźmy teraz do fundamentów nowej architektury.
![NVIDIA GeForce RTX 2070, 2080 i 2080 Ti - Architektura i specyfikacja [4]](https://www.purepc.pl/image/mini_recenzja/2018/09/12_nvidia_geforce_rtx_2070_2080_i_2080_ti_architektura_i_specyfikacja_3_b.png)
Mapa układów TU102 i TU104 - raczej nie trudno odgadnąć, który jest który
![NVIDIA GeForce RTX 2070, 2080 i 2080 Ti - Architektura i specyfikacja [5]](https://www.purepc.pl/image/mini_recenzja/2018/09/12_nvidia_geforce_rtx_2070_2080_i_2080_ti_architektura_i_specyfikacja_4_b.png)
Poniżej najsłabszy z rodziny GeForce RTX - układ TU106 stosowany w RTX 2070
![NVIDIA GeForce RTX 2070, 2080 i 2080 Ti - Architektura i specyfikacja [21]](https://www.purepc.pl/image/mini_recenzja/2018/09/12_nvidia_geforce_rtx_2070_2080_i_2080_ti_architektura_i_specyfikacja_20_b.png)
Rdzenie RT - zupełnie nowa kategoria jednostek obliczeniowych, nieobecna w rdzeniach Pascal i Volta, oddelegowana wyłącznie do obliczeń związanych ze śledzeniem promieni za pomocą algorytmu BVH (Bounding Volume Hierarchy). Chociaż ray tracing to wcale niemłoda metoda generowania obrazu, dotychczas brakowało cywilnym maszynom mocy obliczeniowej, żeby w czasie rzeczywistym sprostać takiemu zadaniu. A tutaj naprawdę jest co liczyć, bowiem wszystkie obiekty odbijają światło, co pozwala tworzyć fotorealistyczne trójwymiarowe sceny, nawet z uwzględnieniem uproszczonego modelu interakcji z otoczeniem. Pomimo, iż algorytm analizuje tylko te źródła, które bezpośrednio trafiają do obserwatora, wymaga to mocnej maszyny. W przypadku obrazów statycznych nie stanowiło to większego problemu, ale renderowanie w czasie rzeczywistszym jest znacznie bardziej zasobożerne. Dedykowane ray tracingowi rdzenie RT posiadają dwie wyspecjalizowane jednostki przyspieszające (m.in. testowanie przecięć promieni / trójkątów) współpracujące z zaawansowanym filtrowaniem odszumiania oraz interfejsami API kompatybilnymi z NVIDIA RTX, odciążając SM zajęte pozostałymi operacjami. Wzrost wydajności względem GeForce GTX 1000 przy wykorzystaniu pakietu NVIDIA RTX stworzonego dla deweloperów, bazującego na DirectX Raytracing (DXR), powinien być przynajmniej dziesięciokrotny (biorąc pod uwagę wydajność wyrażoną GR/s). Swoją drogą, nasz "przeciek" o dedykowanych rdzeniach RT okazał się trafiony.
![NVIDIA GeForce RTX 2070, 2080 i 2080 Ti - Architektura i specyfikacja [6]](https://www.purepc.pl/image/mini_recenzja/2018/09/12_nvidia_geforce_rtx_2070_2080_i_2080_ti_architektura_i_specyfikacja_5_b.png)
Ray tracing od strony sprzętowej i programowej (Battlefield V)
![NVIDIA GeForce RTX 2070, 2080 i 2080 Ti - Architektura i specyfikacja [7]](https://www.purepc.pl/image/mini_recenzja/2018/09/12_nvidia_geforce_rtx_2070_2080_i_2080_ti_architektura_i_specyfikacja_6_b.png)
Rdzenie Tensor - wyspecjalizowane jednostki zaprojektowane do uczenia maszynowego i budowy sieci neuronowych, wykonujące obliczenia w macierzowe przydatne w ściśle określonych scenariuszach. Wprowadzone w architekturze Volta, znalazły bardziej konsumenckie zastosowanie również w Turingu, gdzie odpowiadają między innymi za aktywne wspomaganie przetwarzania obrazu i obliczeń graficznych. Rdzenie Tensor powinny być również użyteczne w przypadku FP16 oraz wsparciu obliczeń asynchronicznych., toteż kondycja architektury Turing w niskopoziomowych API powinna wymiernie wzrosnąć. Lista możliwych zastosowań jest jednak znacznie dłuższa, ponieważ przy odpowiednim zaprogramowaniu (NVIDIA NGX) mogą z powodzeniem np. uzupełniać brakujące elementy w niekompletnych obrazach. Tensory w architekturze Turing zostały też usprawnione względem tych stosowanych w Volcie, dodano im precyzyjne tryby INT8 i INT4, a każdy pojedynczy rdzeń może wykonać do 64 operacji zmiennoprzecinkowych FMA (Fused Multiply-Add) przy połowicznym obciążeniu FP16.
![NVIDIA GeForce RTX 2070, 2080 i 2080 Ti - Architektura i specyfikacja [8]](https://www.purepc.pl/image/mini_recenzja/2018/09/12_nvidia_geforce_rtx_2070_2080_i_2080_ti_architektura_i_specyfikacja_7_b.png)
Struktura rdzenia Turning oraz model renderowania hybrydowego
![NVIDIA GeForce RTX 2070, 2080 i 2080 Ti - Architektura i specyfikacja [19]](https://www.purepc.pl/image/mini_recenzja/2018/09/12_nvidia_geforce_rtx_2070_2080_i_2080_ti_architektura_i_specyfikacja_18_b.png)
SM Turing - nowa architektura wprowadza usprawnione rdzenie CUDA, będące wersją rozwojową SM (Streaming Multiprocessor) Volty, osiągające nawet 50% wyższą wydajność w cieniowaniu względem tych stosowanych w architekturze Pascal. Imponujący wzrost uzyskano dzięki dwóm kluczowym zmianom. Po pierwsze - Turing obsługuje niezależne kolejkowanie instrukcji, dzięki czemu może wykonywać pewne obliczenia równocześnie z operacjami zmiennoprzecinkowymi, które w poprzednich generacjach GPU spowodowałyby zablokowanie pozostałych rozkazów. Po drugie - ścieżka SM została przeprojektowana w celu zunifikowania pamięci wspólnej, buforowania tekstur oraz pamięci - wszystko w jednym pakiecie. Owocuje to dwukrotnie większą przepustowością pamięci podręcznej L1, potrzebnej w typowych zadaniach jakie wykonuje GPU. Połączenie pamięci podręcznej L1 z pamięcią wspólną zmniejsza opóźnienia i zapewnia wyższą przepustowość, niż implementacja pamięci podręcznej L1 poprzednio stosowana w procesorach graficznych Pascal. O pozostałych zmianach oraz usprawnieniach wspominałem na początku rozdziału - stąd powinna wynikać ewentualna przewaga Turinga nad poprzednikami, pomimo relatywnie niewielkiego wzrostu ilości jednostek cieniujących CUDA.
![NVIDIA GeForce RTX 2070, 2080 i 2080 Ti - Architektura i specyfikacja [10]](https://www.purepc.pl/image/mini_recenzja/2018/09/12_nvidia_geforce_rtx_2070_2080_i_2080_ti_architektura_i_specyfikacja_9_b.png)
Zmiany w pamięci podręcznej i deklarowany wzrost wydajności jednostek cieniujących
![NVIDIA GeForce RTX 2070, 2080 i 2080 Ti - Architektura i specyfikacja [9]](https://www.purepc.pl/image/mini_recenzja/2018/09/12_nvidia_geforce_rtx_2070_2080_i_2080_ti_architektura_i_specyfikacja_8_b.png)
Techniki VRS i TSS - pierwsza (Variable Rate Shading) pozwala dynamicznie kontrolować szybkość wykonywania operacji cieniowania, działających w różnych trybach ułożenia pikseli. Algorytm określa szybkość cieniowania obliczając powierzchnię zadaszenia i wartości prymitywnej (trójkąta), pozwalając na efektywniejsze wykorzystanie zasobów przy jednoczesnej redukcji obciążenia w obszarach ekranu, gdzie cieniowanie w pełnej rozdzielczości nie przynosi żadnych zauważalnych korzyści. VRS pozwala zatem uzyskać wysoką lecz bezstratną płynność obrazu. Technika TSS (Texture-Space Shading) umożliwia z kolei cieniowanie obiektów w „prywatnej przestrzeni” współrzędnych (tekstur) zapisanych w pamięci, skąd określone dane są pobierane. Dzięki możliwości buforowania wyników i ponownego użycia / próbkowania, programiści mogą wyeliminować duplikację cieniowania lub zastosować różne metody próbkowania, które poprawiają ogólną jakość obrazu. Jak to będzie działać w praktyce niebawem zobaczymy.
NVIDIA Turing to architektura oferująca na papierze bardzo dużo ciekawych oraz innowacyjnych rozwiązań, a także usprawnień w obrębie samego jądra. Zdecydowanie bliżej jej również do Volty, niż Pascala.
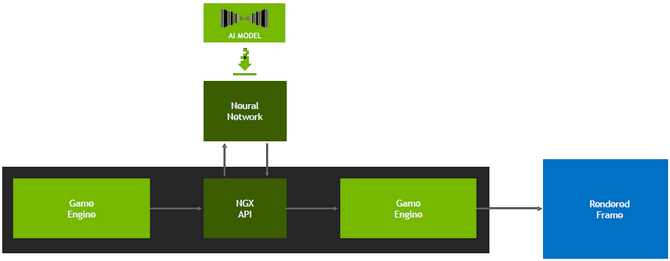
NVIDIA NGX i DLSS - pierwsza to technika oparta na sztucznej inteligencji oraz głębokim uczeniu (Deep Learning) wykorzystująca głębokie sieci neuronowe (DNN) oraz rdzenie Tensor do wykonywania funkcji opartych na sztucznej inteligencji. W założeniach powinna przyspieszać oraz usprawniać obróbkę grafiki na etapie komunikowania z silnikiem. Co ciekawe, SI będzie nieprzerwanie uczyła się kolejnych gier komputerowych, a całym procesem zajmą się centra NVIDII, toteż z czasem produkcje powinny działać coraz lepiej, bo udostępniane profile będą lepiej zoptymalizowane (dostępne w sterowniku albo w formie patcha, który odczytają Tensory). Bezpośrednio z NVIDIA NGX i Tensorami związana jest również technika DLSS (Deep Learning Super-Sampling), nowe wygładzanie wykorzystujące sieci neuronowe do eliminacji nierównych krawędzi, poprawienia ostrości obrazu czy dobrania najlepszego koloru dla poszczególnych pikseli. DLSS zapewnia o wiele wyższą jakość od wygładzania TAA, bowiem TAA renderuje przy rozdzielczości docelowej, a następnie łączy ramki odejmując szczegóły. DLSS pozwala na szybsze renderowanie przy mniejszej liczbie próbek wejściowych, a ostateczny wynik jest podobny lub lepszy przy mniejszej zasobożerności. Co więcej, algorytm zapamiętuje wygląd konkretnych klatek (64), tworząc kompletny obraz wysokiej jakości. Deweloperzy mogą samemu zaimplementować obydwie nowości albo skorzystać z bezpłatnej pomocy NVIDII, która dysponując komputerem Saturn V przygotuje im odpowiedni profil (wolontariat jest podyktowany chęcią popularyzacji tej techniki). NVIDIA NGX i DLSS nie będą jednak działać na architekturze Pascal, starszych i konkurencyjnych. Obecność DLSS potwierdzono w m.in.: Atomic Heart, Final Fantasy XV, Hitman 2, Serious Sam 4, Shadow of the Tomb Raider.
![NVIDIA GeForce RTX 2070, 2080 i 2080 Ti - Architektura i specyfikacja [14]](/files/Image/news/2018/09/dlss_nvidia_turing_1.jpg)
Przewaga DLSS nad TAA ma być druzgocąca przy zachowaniu podobnego obciążenia
Pamięci GDDR6 - Volta wykorzystywała pamięci HBM2 zapewniające ogromną przepustowość, wynoszącą w przypadku NVIDIA Titan V ponad 652 GB/s, jednak takie moduły znacznie podnosiły cenę urządzenia. Problemem okazywała się również ograniczona dostępność, związana z trudniejszym procesem wytwarzania od zwykłych GDDR. Dlatego w konsumenckich kartach graficznych GeForce RTX 2000 zastosowano pamięci GDDR6, pracujące z wysokimi zegarami (14 000 MHz), zapewniającymi bardzo zbliżoną przepustowość. NVIDIA zadbała także o właściwą implementację nowych modułów, bowiem pamięci wspiera szereg technologii zwiększających ich efektywność, wydajność energetyczną, redukujących szumy, minimalizujących zmiany spowodowane temperaturą i napięciem zasilania. Turing otrzymał także bardziej zaawansowane mechanizmy bezstratnej kompresji tekstur, zmniejszające zapotrzebowanie na przepustowość pamięci. Silnik GPU dysponuje wieloma różnymi algorytmami, które określają najbardziej efektywny sposób kompresowania, zmniejszając zarazem ilość przenoszonych danych z pamięci graficznej do pamięci podręcznej L2 (dodatkowo dwukrotnie powiększonej względem Pascali), a także zmniejszając ilość danych przesyłanych między klientami i buforem ramki.
![NVIDIA GeForce RTX 2070, 2080 i 2080 Ti - Architektura i specyfikacja [11]](https://www.purepc.pl/image/mini_recenzja/2018/09/12_nvidia_geforce_rtx_2070_2080_i_2080_ti_architektura_i_specyfikacja_10_b.png)
Pamięci GDDR6 i korzyści płynące z nowego mechanizmu kompresji tekstur
![NVIDIA GeForce RTX 2070, 2080 i 2080 Ti - Architektura i specyfikacja [12]](https://www.purepc.pl/image/mini_recenzja/2018/09/12_nvidia_geforce_rtx_2070_2080_i_2080_ti_architektura_i_specyfikacja_11_b.png)
NVIDIA NVLink - karty graficzne NVIDIA RTX 2080 / 2080 Ti zamiast tradycyjnego złącza SLI otrzymały NVIDIA NVLink drugiej generacji, które umożliwia ultraszybką komunikację i oprócz wysokiej przepustowości zapewnia też niskie opóźnienia między procesorami graficznymi. NVIDIA NVLink zapewnia bardziej równomierne obciążenie układów, zaś stosowana w akceleratorach Quadro również bezpośredni dostęp do pamięci innych podłączonych procesorów graficznych tzn. łączenie przestrzeni VRAM. Niestety, wersja przygotowana dla GeForce RTX 2000 będzie podobno tylko rozwinięciem SLI, dlatego konsolidacja pamięci graficznej tutaj nie występuje, chociaż w przyszłości implementacja takiego mechanizmu jest niewykluczona. Bezproblemowo mają jednak działać wszystkie profile multi-GPU jakie dotychczas powstały. Układ TU102 posiada dwa złącza NVLink x8, podczas gdy TU104 tylko jedno x8, a każde może dostarczyć do 25 GB/s, a całkowita łączna dwukierunkowa przepustowość tej technologii może wynosić do 100 GB/s. Jest to zatem bardziej nowoczesne rozwiązanie od podwójnego mostka SLI HB oraz PCI-Express 3.0 stosowanych w układach Pascal, aczkolwiek obsługiwane są konfiguracje z maksymalnie dwoma kartami graficznymi (od RTX 2070 SUPER). Mostka nie znajdziemy w zestawie - jest dodatkowo płatny i trzeba tutaj szykować 79 USD.
VirtualLink i HDR - spośród pozostałych zmian i wprowadzonych nowości warto jeszcze wymienić Virtual Link. Obsługa systemów VR wymaga obecnie podłączenia wielu kabli, pogarszających ergonomię całego zestawu, więc NVIDIA postanowiła uzdrowić tę poplątaną sytuację. Karty GeForce RTX 2000 otrzymały sprzętową obsługę VirtualLink, będącego nowym otwartym standardem korzystającym z pojedynczego złącza USB Typ-C, a pomysł wspierają m.in. NVIDIA, Oculus, Valve, Microsoft i AMD. VirtualLink obsługuje jednocześnie 4 pasma DisplayPort (HBR3) w komitywie ze łączem SuperSpeed USB 3 przeznaczonym do osprzętu od śledzenia ruchu. Pozwoli to przystosować zestawy VR dla większej ilości urządzeń, zwłaszcza tych mobilnych, gdzie z różnych względów możliwe jest umieszczenie tylko pojedynczego USB Typ-C. Procesory Turing zyskały też całkowicie nowy silnik wyświetlania, przeznaczony dla nowej generacji wyświetlaczy, obsługujących wyższe rozdzielczości, szybsze odświeżanie i HDR. Karty standardowo otrzymały DisplayPort 1.4a umożliwiający wyświetlenie rozdzielczości 8K przy 60 Hz, a także obsługują technologię VESA Display Stream Compression (DSC) 1.2, zapewniającą wyższą bezstratną kompresję obrazu. Poza tym, nowy silnik może się pochwalić natywnym przetwarzaniem HDR z równoczesnym mapowaniem tonów w wyświetlanym potoku. Na zakończenie otrzymaliśmy ulepszony enkoder NVENC dodający obsługę H.265 (HEVC) 8K 30 FPS oraz dekodowanie HDR HEVC YUV444 10 / 12b przy 30 FPS, H.264 8K i VP9 10 / 12b HDR.
- « pierwsza
- ‹ poprzednia
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- …
- następna ›
- ostatnia »
- SPIS TREŚCI -
- 1 - Jeszcze jeden Turing w wersji SUPER
- 2 - NVIDIA Turing - trochę więcej o architekturze
- 3 - NVIDIA GeForce RTX 2080 SUPER - Budowa i parametry techniczne
- 4 - Platforma testowa i wykorzystane sterowniki
- 5 - Test wydajności RTX 2080 SUPER - 3DMark Time Spy
- 6 - Test wydajności RTX 2080 SUPER - Assassin's Creed: Odyssey
- 7 - Test wydajności RTX 2080 SUPER - Battlefield V
- 8 - Test wydajności RTX 2080 SUPER - Hitman 2
- 9 - Test wydajności RTX 2080 SUPER - Kingdom Come: Deliverance
- 10 - Test wydajności RTX 2080 SUPER - Metro Exodus
- 11 - Test wydajności RTX 2080 SUPER - Shadow of the Tomb Raider
- 12 - Test wydajności RTX 2080 SUPER - Witcher 3: Wild Hunt
- 13 - Test wydajności RTX 2080 SUPER - Wolfenstein II: The New Colossus
- 14 - Overclocking - maksymalne stabilne zegary
- 15 - Test wydajności RTX 2080 SUPER - 3DMark Time Spy (OC)
- 16 - Test wydajności RTX 2080 SUPER - Battlefield V (OC)
- 17 - Test wydajności RTX 2080 SUPER - Witcher 3: Wild Hunt (OC)
- 18 - Test wydajności RTX 2080 SUPER - Wolfenstein II: The New Colossus (OC)
- 19 - Test wydajności RTX 2080 SUPER - Battlefield V (DXR i DLSS)
- 20 - Test wydajności RTX 2080 SUPER - Metro: Exodus (DXR i DLSS)
- 21 - Test wydajności RTX 2080 SUPER - Shadow of the Tomb Raider (DXR i DLSS)
- 22 - Pobór mocy - Spoczynek i obciążenie (Battlefield V)
- 23 - Pomiar temperatur - Spoczynek i obciążenie (Wiedźmin 3)
- 24 - Pomiar głośności - Spoczynek i obciążenie (Wiedźmin 3)
- 25 - Podsumowanie - Do trzech razy sztuka?

Powiązane publikacje

Test karty graficznej KFA2 GeForce RTX 5080 1-Click OC - Efektowne podświetlenie ARGB i regulowana podpórka w komplecie
173
Jaka karta graficzna do gier? Kupić AMD Radeon czy NVIDIA GeForce? Polecane karty graficzne na czerwiec 2025
162
Test wydajności DOOM: The Dark Ages - Path Tracing to piekielne wymagania sprzętowe. Porównanie wydajności i jakości grafiki
550
Test kart graficznych AMD Radeon RX 9060 XT vs NVIDIA GeForce RTX 5060 Ti - Waga kogucia doładowana 16 GB pamięci?
455





