





Test Radeon HD 7970 - Nowy król wydajności i pogromca GTX 580
- SPIS TREŚCI -
- 0 - AMD przejmuje inicjatywę
- 1 - HD 7970 - Tahiti XT
- 2 - Graphics Core Next
- 3 - DX11.1, Eyefinity 2.0 i HD3D
- 4 - ZeroCore Power i inne cuda
- 5 - Platforma testowa
- 6 - 3DMark, Heaven, Stone
- 7 - AvP, Batman, Battlefield 3
- 8 - Crysis: Warhead, Crysis 2
- 9 - DiRT 3, GTA4: EfLC
- 10 - Mafia 2, Metro 2033
- 11 - Stalker: COP, Starcraft 2
- 12 - TES V: Skyrim, Wiedźmin 2
- 13 - Testy GPGPU na HD 7970
- 14 - Chłodzenie i Pobór Energii
- 15 - Overclocking HD 7970
- 16 - Podsumowanie
Filozofia Graphic Core Next
Opis architektury GCN (Graphic Core Next) będącej kręgosłupem HD 7900 zaczniemy od małej wycieczki w przeszłość. Wraz z pierwszym GPU zgodnym z DirectX 9 wtedy jeszcze sygnowanym logiem ATI (Radeon 9700 - R300), AMD wprowadziło projekt architektury VLIW (Very Long Instruction Word). Ponieważ obliczenia związane z generowaniem grafiki sprowadzały się do obliczeń wykonywanych na 4 komponentach zmiennoprzecinkowych i jednej (np. odpowiedzialnej za światło) wartości stałej - stąd też nazwa VLIW5. Wraz z narodzinami Radeona HD 2900 (R600) projekt VLIW5 zachowano, bowiem wciąż spełniał on swoją rolę. Gry w większości nadal operowały z wykorzystaniem DirectX 9, czyli sprowadzały się do operacji na 5-cio elementowych wartościach.

Ulepszana architektura VLIW5 dotarła nawet do HD 5870, po czym przy badaniach nad następcą okazało się, że w typowym obciążeniu grami na każde 5 procesorów strumieniowych (SP) wykorzystywano średnio jedynie 3,4. Nie był to wynik tragiczny, niemniej jednak ze średnio 1 niewykorzystanym SP postanowiono coś zrobić. Dodatkowo aspekt obliczeń z wykorzystaniem GPU zaczynał przybierać na sile. I tak wraz z Caymanem vel. Radeonem HD 6900 pojawił się pod strzechą nowy skurczony VLIW4, w którym z 5 SP w postaci 4 ALU (jednostka arytmetyczno-logiczna) i jednej t-jednostki odpowiedzialnej za transcendentalne operacje pozostawiono 4 ALU. T-operacje wykonywać miała teraz trójka SP. Wydajność takich skróconych SPU (Streaming Processor Unit) była z grubsza taka sama. Cały zbudowany z nich SIMD miał jednak mniej SP, dzięki czemu zyskaliśmy więcej miejsca na kolejne SIMD (Cayman miał ich 24, poprzednik Cypress 20). I tutaj tkwił główny zysk, więcej SIMD to więcej obliczeń wykonanych na raz, chociażby na liczbach zmiennoprzecinkowych podwójnej precyzji (FP64).
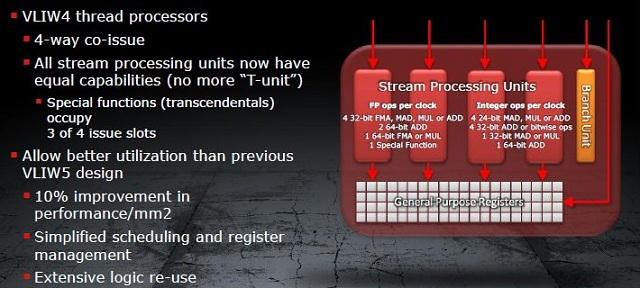
Rdzeń oparty o VLIW4 sprowadza się do gęstej sieci bardzo wielu SP oraz pamięci podręcznej, zaś kolejkowaniem zajmuje się kompilator. To on korzystając z przewagi znajomości całego programu na przód inteligentnie przydziela zadania. Problem w tym, że kompilator nie jest w stanie analizować warunków, które wymagają wpierw uruchomienia programu i dostarczenia danych, dlatego kolejkowanie to nazywane jest statycznym. Wszystko to powoduje, że dla poprawnej pracy architektury VLIW zadania muszą się dobrze na niej mapować. Wszelkiej maści skomplikowane operacje, z którymi proste ALU nie są sobie w stanie poradzić czy instrukcje niedające się łatwo kolejkować przez zależności i konflikty, są niewskazane dla VLIW. O ile gry i zadania jakie nakładają one na GPU spełniają warunki poprawnej współpracy, to przy obliczeniach GPGPU dziwactwa VLIW zaczynają dawać się we znaki.
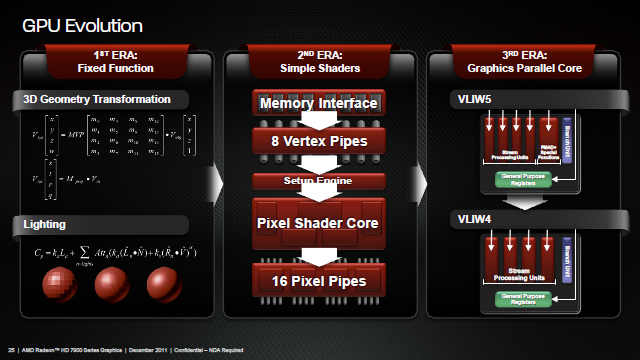
Powyższe akapity mogą rodzić pytanie: po co AMD nowa architektura skoncentrowana na wsparciu obliczeń GPGPU, skoro VLIW dobrze radzi sobie z grami i tym samym na rynku konsumenckim? Dłuższą odpowiedzią są plany AMD związane z Fusion, czyli tworzeniu GPU wspomagających CPU w obliczeniach. Krótsza odwiedź jest znacznie prostsza - muszą. W 2011 roku, a dokładniej jego trzecim kwartale rozwiązania profesjonalne Nvidii (Quadro i Tesla) osiągnęły zysk operacyjny na poziomie 95 milionów dolarów przy 230 milionach przychodów. Dla porównania część konsumencka osiągnęła 146 milionów zysków, ale przy aż 644 milionach przychodów. Rynek profesjonalny ma znacznie wyższy margines zysków i o ile na rynku konsumenckim AMD jest w stanie dorównać Nvidii, to jednak ci drudzy zarabiają więcej. AMD musi wgryźć się w ten profesjonalny segment żeby się utrzymać i stąd nowa architektura GCN (Graphic Core Next).
Graphic Core Next od kuchni
Czym więc AMD zastąpiło VLIW? Tradycyjnym wektorowym procesorem SIMD (Single Instruction, Multiple Data). Elementy architektury GCN nie przekładają się jednak bezpośrednio na te w architekturze VLIW, toteż nie należy mylić SIMD w GCN będącego pełnoprawnym SIMD zdolnym do pracy na wektorach 16-to elementowych z SIMD w Caymanie, będącym zlepkiem 16-tu SPU. W GCN do pojedynczego SIMD dostarcza się jedną instrukcję oraz 16 elementów danych, które przetwarzane są w ciągu jednego cyklu zegara. Podobnie jak w poprzednich architekturach również tutaj rdzeń AMD operuje na tak zwanych "falach" (wavefronts), składających się z 64 wartości/pikseli i listy instrukcji do wykonania co oznacza, że do wykonania całej fali dla jednej instrukcji potrzeba 4 cykli. SIMD zbudowane z 16-tu jednostek arytmetyczno-logicznych (ALU) tworzących wektor (Vector Unit) oraz 64KB rejestru danych (Vector Register) stanowi najmniejszy fundamentalny element nowej architektury.
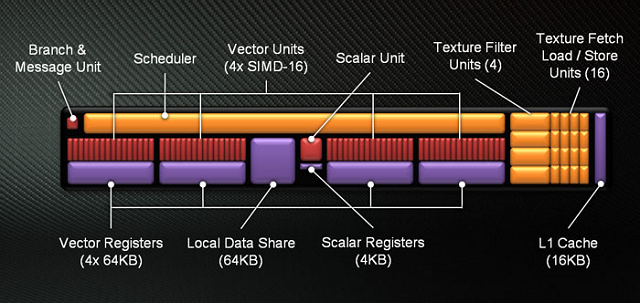
Cztery SIMD wraz z grupą elementów pomocniczych tworzą najmniejszą samodzielną jednostkę GCN. Mowa o Compute Unit (CU) - Jednostce Obliczeniowej. Lista elementów pomocniczych składa się ze sprzętowego planowania/harmonogramu (Scheduler), jednostki rozgałęziającej (Branch & Message Unit), pamięci podręcznej L1 (L1 Cache), pamięci współdzielonej (Local Data Share), czterech jednostek tekstur każdej złożonej z filtra (Texture Filter Unit) i czterech jednostek pobierania ładowania/przechowywania (Texture Fetch Load/Store Unit) oraz finalnie jednostki skalarnej (Scalar Unit) wraz z własnym rejestrem (Scalar Registers). Jednostka skalarna odpowiedzialna jest za operacje arytmetyczne których proste ALU w SIMD nie są w stanie wykonać, lub robiłyby to nieefektywnie. Takimi operacjami są np. warunki kondycyjne (if/then), czy operacje transcendentalne.
Pojedynczy CU składa się więc z czterech SIMD i jest w stanie operować na czterech różnych falach. GCN stara się więc wykonywać jedną instrukcję spośród kilku fal, co w rezultacie powoduje, że korzysta z równoważności poziomu wątków - TLP (Thread Level Parallelism) i charakter jego pracy jest spójny tzn. jego wydajność jest stabilna oraz pozbawiona skoków. Tego właśnie oczekuję się od architektury dobrej do wspomagania obliczeń. Dla porównania poprzednik (Cayman) próbowałby wykonać wiele instrukcji z tej samej fali równolegle, co w przypadku jeśli instrukcje były zależne od siebie powodowało, że musiał pozwolić części swoich ALU nie robić nic. GCN w takiej sytuacji do pracy weźmie następną niezależną falę, chociażby z innego zadania. Cayman jest więc zgodny z równoważnością poziomu instrukcji - ILP (Instruction Level Parallelism) i w zależności od sytuacji jego wydajność skakała od wysokiej (brak zależności między instrukcjami - np. gry, haszowanie haseł) do niskiej (jedna instrukcja zależy od kilku pozostałych i musi być obliczana samodzielnie - np. kompresja tekstur).
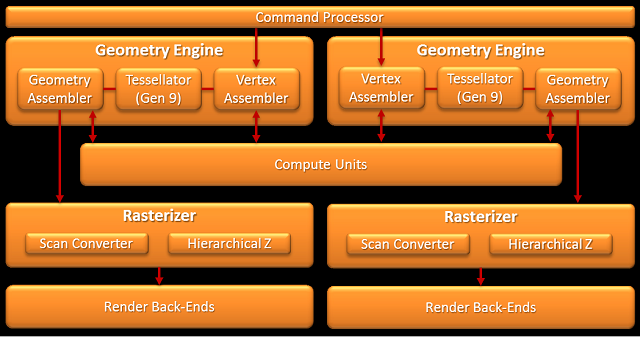
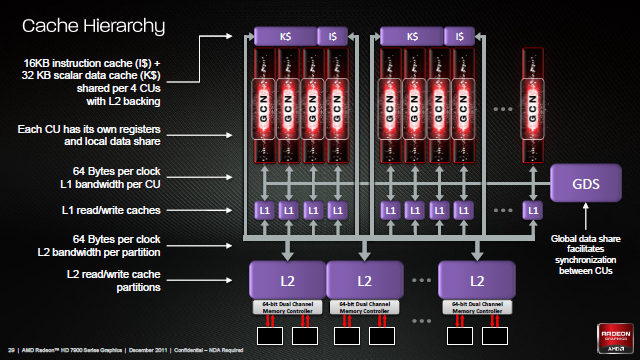
Finalny rdzeń zbudowany jest z pewnej liczby jednostek obliczeniowych (CU). W przypadku Tahiti jest to 32 CU, co daje 128 SIMD każde po 16 SP, łącznie 2048 SP w całym GPU. Oczywiście poza samymi CU rdzeń graficzny dopełnia rzesza dodatkowych elementów. Mamy tutaj tak zwany fronend w skład którego wchodzi m.in. procesor komend (Command Processor) rozdzielający zadania do dwóch silników geometrycznych (Geometry Engine), zaś w nich nowych teselatorów 9-tej generacji, jak i dwóch silników obliczeniowych (ACE - Asynchronous Compute Engine) odpowiedzialnych za "karmienie" CU. Za CU z kolei mamy osiem końcówek renderowania, a w nich po cztery ROPy (Render Output Unit, lub bardziej poprawnie Raster Operations Pipeline) koloru i szesnaście jednostek bufora Z/szablonowego. Jest też pamięć podręczna L2, sześć dwu-kanałowych 64-bitowych kontrolerów pamięci, oraz zestaw kontrolerów odpowiedzialnych m.in. za szynę PCI-E, wyświetlanie (Eyefinity Display Controllers), Universal Video Decoder (UDV) czy Video Codec Engine (VCE). Podobnie jak w Caymanie każdy z silników geometrycznych jest w stanie teoretycznie wytworzyć 1 trójkąt na cykl zegara, jednak dzięki poprawkom sprawności Tahiti powinno być znacznie szybsze od Caymana.

AMD w Caymanie nie było w stanie osiągnąć teoretycznej wydajności jednostek ROP nawet w testach syntetycznych. W Tahiti dla nadążania za nowymi grami AMD musiało poprawić ich wydajność. Możliwości były dwie: Zwiększyć ich liczbę albo zwiększyć ich wydajność np. poprawiając podsystem pamięci. Z racji, że AMD praktycznie osiągnęło limit możliwości pamięci GDDR5, najprostszym rozwiązaniem było rozdzielenie dotychczas sparowanych z kontrolerami pamięci ROPów (jak to jest w Caymanie) i zwiększenie ilości kontrolerów, a co za tym szerokości całkowitej szyny i jej przepustowości. I tak Tahiti otrzymało 8 bloków renderowania z ROPami i 6 odseparowanych od nich kontrolerów pamięci, dzięki czemu w testach wypełniania pikseli jest ponad 50% wydajniejszy od starszego brata HD 6970. Oczywiście rozdzielenie ROPów i kontrolerów musiało pociągnąć za sobą jakieś negatywne aspekty jak chociażby potencjalnie wyższy czas dostępu, ale ich wpływu nie znamy, natomiast dwa dodatkowe kontrolery zaowocowały także o 50% większą pamięcią cache L2 z racji, że z każdym kontrolerem sparowane jest 128KB tejże pamięci podręcznej.
Koniec końców jeśli AMD odrobiło pracę domową, GCN powinno charakteryzować się znacznie wyższą wydajnością obliczeniową GPGPU, jednocześnie zachowując wydajność w grach w stosunku do architektury VLIW4 (dla podobnej liczby SP). Właściwe rozłożenie wykonywania operacji cieniowania w grach na CU w GCN jest zupełnie inne niż na SPU w VLIW, ale prędkość powinna być podobna. Dodatkowo gry wykorzystujące DirectCompute powinny zyskać dzięki poprawionej wydajności GPGPU. Oczywiście nowa architektura to nie koniec nowości jakie serwuje nam AMD w ich nowym flagowym modelu HD 7970. O pozostałych możecie przeczytać na następnej stronie...
- « pierwsza
- ‹ poprzednia
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- …
- następna ›
- ostatnia »
- SPIS TREŚCI -
- 0 - AMD przejmuje inicjatywę
- 1 - HD 7970 - Tahiti XT
- 2 - Graphics Core Next
- 3 - DX11.1, Eyefinity 2.0 i HD3D
- 4 - ZeroCore Power i inne cuda
- 5 - Platforma testowa
- 6 - 3DMark, Heaven, Stone
- 7 - AvP, Batman, Battlefield 3
- 8 - Crysis: Warhead, Crysis 2
- 9 - DiRT 3, GTA4: EfLC
- 10 - Mafia 2, Metro 2033
- 11 - Stalker: COP, Starcraft 2
- 12 - TES V: Skyrim, Wiedźmin 2
- 13 - Testy GPGPU na HD 7970
- 14 - Chłodzenie i Pobór Energii
- 15 - Overclocking HD 7970
- 16 - Podsumowanie
Powiązane publikacje

Test karty graficznej KFA2 GeForce RTX 5080 1-Click OC - Efektowne podświetlenie ARGB i regulowana podpórka w komplecie
173
Jaka karta graficzna do gier? Kupić AMD Radeon czy NVIDIA GeForce? Polecane karty graficzne na czerwiec 2025
162
Test wydajności DOOM: The Dark Ages - Path Tracing to piekielne wymagania sprzętowe. Porównanie wydajności i jakości grafiki
550
Test kart graficznych AMD Radeon RX 9060 XT vs NVIDIA GeForce RTX 5060 Ti - Waga kogucia doładowana 16 GB pamięci?
455





