





Test XNOTE P370EM z 2x Radeon HD 7970M za 10000 zł
- SPIS TREŚCI -
- 0 - XNOTE dla kombinatorów
- 1 - Mobilne GCN - Architektura
- 2 - DX11.1, Eyefinity 2.0 i HD3D
- 3 - ZeroCore Power i inne cuda
- 4 - XNOTE P370EM - Budowa
- 5 - XNOTE P370EM - Specyf.
- 6 - Testy syntetyczne
- 7 - Testy praktyczne
- 8 - Testy w grach cz. 1
- 9 - Testy w grach cz. 2
- 10 - 7970M vs Desktop w grach
- 11 - Temperatury i kultura pracy
- 12 - Czas pracy na baterii
- 13 - Podsumowanie
Graphics Core Next - Architektura
Poprzednia generacja mobilnych układów graficznych AMD, Mobility Radeon HD 6000, stanowiła rozwinięcie popularnych GPU z serii HD 5000. Układy te były raczej udane, co szczególnie było widoczne w przypadku modeli z niższej półki cenowej, jak przykładowo Radeon HD 6770M. Laptopy z tymi GPU sprzedawały się bardzo dobrze ze względu na niezły stosunek wydajności do ceny. Jednak w grupie mocnych, mobilnych kart graficznych seria HD 6000 wypadała przeważnie nieco gorzej od konkurencji, czyli rodziny NVIDIA Fermi - zarówno pod względem wydajności, jak i poboru mocy czy ilości wydzielanego ciepła, co pokazaliśmy w teście notebooków dla graczy na początku tego roku. Seria Mobility Radeon HD 7000 to jednak pełne zerwanie z tradycją. Układy te oparto bowiem na nowej architekturze GCN (Graphics Core Next), znanej z rodziny desktopowych układów graficznych Radeon HD 7000.
Co zatem takiego wyjątkowego wprowadza GCN do nowych kart graficznych AMD z rodziny Wimbledon? Przede wszystkim rezygnację z architektury VLIW na rzecz tradycyjnego wektorowego procesora SIMD. W GCN do pojedynczego SIMD dostarcza się jedną instrukcję oraz 16 elementów danych, które przetwarzane są w ciągu jednego cyklu zegara. Podobnie jak w poprzednich architekturach również tutaj rdzeń AMD operuje na tak zwanych "falach" (wavefronts), składających się z 64 wartości/pikseli i listy instrukcji do wykonania co oznacza, że do wykonania całej fali dla jednej instrukcji potrzeba 4 cykli. SIMD zbudowane z 16-tu jednostek arytmetyczno-logicznych (ALU) tworzących wektor (Vector Unit) oraz 64KB rejestru danych (Vector Register) stanowi najmniejszy fundamentalny element nowej architektury.
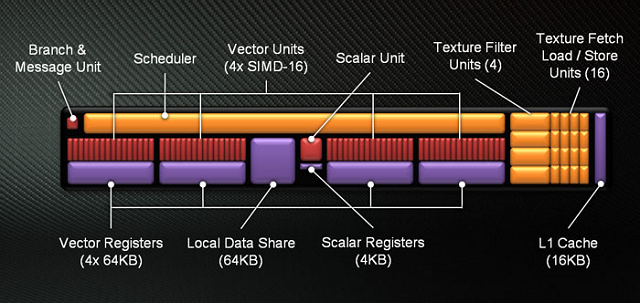
Cztery SIMD wraz z grupą elementów pomocniczych tworzą najmniejszą samodzielną jednostkę GCN. Mowa o Compute Unit (CU) - Jednostce Obliczeniowej. Lista elementów pomocniczych składa się ze sprzętowego planowania/harmonogramu (Scheduler), jednostki rozgałęziającej (Branch & Message Unit), pamięci podręcznej L1 (L1 Cache), pamięci współdzielonej (Local Data Share), czterech jednostek tekstur każdej złożonej z filtra (Texture Filter Unit) i czterech jednostek pobierania ładowania/przechowywania (Texture Fetch Load/Store Unit) oraz finalnie jednostki skalarnej (Scalar Unit) wraz z własnym rejestrem (Scalar Registers). Jednostka skalarna odpowiedzialna jest za operacje arytmetyczne których proste ALU w SIMD nie są w stanie wykonać, lub robiłyby to nieefektywnie. Takimi operacjami są np. warunki kondycyjne (if/then), czy operacje transcendentalne.
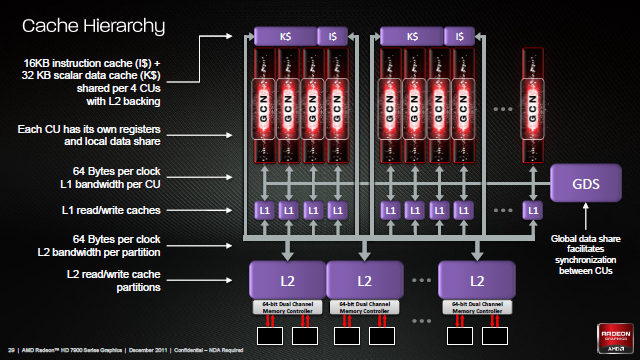
Pojedynczy CU składa się więc z czterech SIMD i jest w stanie operować na czterech różnych falach. GCN stara się więc wykonywać jedną instrukcję spośród kilku fal, co w rezultacie powoduje, że korzysta z równoważności poziomu wątków - TLP (Thread Level Parallelism) i charakter jego pracy jest spójny tzn. jego wydajność jest stabilna oraz pozbawiona skoków. Tego właśnie oczekuję się od architektury dobrej do wspomagania obliczeń. Dla porównania, poprzednik (Blackcomb) próbowałby wykonać wiele instrukcji z tej samej fali równolegle, co w przypadku jeśli instrukcje były zależne od siebie powodowało, że musiał pozwolić części swoich ALU nie robić nic. GCN w takiej sytuacji do pracy weźmie następną niezależną falę, chociażby z innego zadania. Blackcomb jest więc zgodny z równoważnością poziomu instrukcji - ILP (Instruction Level Parallelism) i w zależności od sytuacji jego wydajność skakała od wysokiej (brak zależności między instrukcjami - np. gry, haszowanie haseł) do niskiej (jedna instrukcja zależy od kilku pozostałych i musi być obliczana samodzielnie - np. kompresja tekstur).
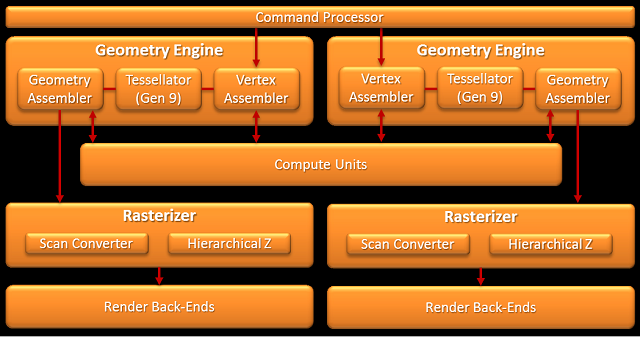
Finalny rdzeń zbudowany jest z pewnej liczby jednostek obliczeniowych (CU). Oczywiście poza samymi CU, rdzeń graficzny dopełnia rzesza dodatkowych elementów. Mamy tutaj tak zwany fronend w skład którego wchodzi m.in. procesor komend (Command Processor), rozdzielający zadania do dwóch silników geometrycznych (Geometry Engine), zaś w nich nowych teselatorów 9-tej generacji, jak i dwóch silników obliczeniowych (ACE - Asynchronous Compute Engine) odpowiedzialnych za "karmienie" CU. Za CU z kolei mamy osiem końcówek renderowania, a w nich po cztery ROPy (Render Output Unit, lub bardziej poprawnie Raster Operations Pipeline) koloru i szesnaście jednostek bufora Z/szablonowego. Jest też pamięć podręczna L2, cztery dwu-kanałowe 64-bitowe kontrolery pamięci, oraz zestaw kontrolerów odpowiedzialnych m.in. za szynę PCI-E, wyświetlanie (Eyefinity Display Controllers), Universal Video Decoder (UDV) czy Video Codec Engine (VCE). Podobnie jak w Blackcombie każdy z silników geometrycznych jest w stanie teoretycznie wytworzyć 1 trójkąt na cykl zegara, jednak dzięki poprawkom sprawności Wimbledon powinien być znacznie szybszy od Blackcomba.

Koniec końców AMD odrobiło pracę domową, ponieważ GCN charakteryzuje się znacznie wyższą wydajnością obliczeniową GPGPU, jednocześnie zachowując wydajność w grach w stosunku do architektury VLIW4 (dla podobnej liczby SP). Właściwe rozłożenie wykonywania operacji cieniowania w grach na CU w GCN jest zupełnie inne niż na SPU w VLIW, ale prędkość jest podobna. Dodatkowo gry wykorzystujące DirectCompute powinny zyskać dzięki poprawionej wydajności GPGPU. Oczywiście nowa architektura to nie koniec nowości jakie serwuje nam AMD w ich nowych modelach HD 7800. O pozostałych możecie przeczytać na następnej stronie...
- « pierwsza
- ‹ poprzednia
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- …
- następna ›
- ostatnia »
- SPIS TREŚCI -
- 0 - XNOTE dla kombinatorów
- 1 - Mobilne GCN - Architektura
- 2 - DX11.1, Eyefinity 2.0 i HD3D
- 3 - ZeroCore Power i inne cuda
- 4 - XNOTE P370EM - Budowa
- 5 - XNOTE P370EM - Specyf.
- 6 - Testy syntetyczne
- 7 - Testy praktyczne
- 8 - Testy w grach cz. 1
- 9 - Testy w grach cz. 2
- 10 - 7970M vs Desktop w grach
- 11 - Temperatury i kultura pracy
- 12 - Czas pracy na baterii
- 13 - Podsumowanie

Powiązane publikacje

Test ASUS ROG Zephyrus G16 - Stylowy laptop do gier i pracy z GeForce RTX 4090, Intel Core Ultra 9 185H i ekranem OLED
105
MSI Titan 18 HX to naszpikowany technologiami NVIDIA RTX notebook dla wymagających graczy
8
Jaki laptop kupić? Polecane laptopy do gier, nauki, pracy i multimediów. Poradnik zakupowy na kwiecień i maj 2024
16
Wyłączamy tryb Turbo Boost w laptopach z procesorem Intel Core i9-13900HX. Porównanie temperatur i wydajności w grach
26





