





Test AMD Radeon HD 7970 vs NVDIA GeForce GTX 680 - RetroGPU #1
- SPIS TREŚCI -
- 1 - NVIDIA GeForce GTX 680 vs AMD Radeon HD 7970
- 2 - AMD Radeon HD 7970 - Budowa i parametry techniczne
- 3 - Architektura AMD Graphic Core Next
- 4 - NVIDIA GeForce GTX 680 - Budowa i parametry techniczne
- 5 - Architektura NVIDIA Kepler
- 6 - Platforma testowa i wykorzystane sterowniki
- 7 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - 3DMark Time Spy
- 8 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - Assassin's Creed: Odyssey
- 9 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - Battlefield V
- 10 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - Far Cry: New Dawn
- 11 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - GRID 2019
- 12 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - Kingdom Come: Deliverance
- 13 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - Metro Exodus
- 14 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - Shadow of the Tomb Raider
- 15 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - Witcher 3: Wild Hunt
- 16 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - Wolfenstein II
- 17 - Overclocking - maksymalne stabilne zegary
- 18 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - 3DMark Time Spy (OC)
- 19 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - Metro: Exodus (OC)
- 20 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - Witcher 3: Wild Hunt (OC)
- 21 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - Wolfenstein II (OC)
- 22 - Pobór mocy - Spoczynek i obciążenie (Battlefield V)
- 23 - Pomiar temperatur - Spoczynek i obciążenie (Wiedźmin 3)
- 24 - Pomiar głośności - Spoczynek i obciążenie (Wiedźmin 3)
- 25 - Podsumowanie - Kepler wyjechał na Tahiti
Architektura NVIDIA Kepler
Nvidia w czasie pracy nad Fermim jako priorytet stawiała jego wydajność w stosunku do architektury Tesli (GT200). Zaowocowało to bardzo wydajnym rdzeniem graficznym, któremu daleko było do energooszczędnego rozwiązania zwłaszcza po przeciwstawieniu Fermiego (GF100) z nowym dzieckiem Czerwonych (HD 7970). Nowsze wcielenie Fermiego (GF110) mimo poprawek wciąż kuleje w takim porównaniu. Wraz z projektowaniem Keplera kolejność priorytetów jakie przyświecały Nvidii ulegała więc zmianie. O ile zachowanie tytułu najwydajniejszej jednordzeniowej karty było wciąż istotnym aspektem, to najwyższy priorytet otrzymała energooszczędność. Jednym z największych wkładów w wyższą wydajność z jednego wata jest nowy proces technologiczny wynoszący jak u konkurenta 28 nm. Obrabianiem krzemu dla giganta z Santa Clara zajmują się fabryki TSMC, czyli te same dziergające rdzenie dla kart AMD. Oczywiście Nvidia nie spoczęła na laurach i nowy rdzeń Kepler (GK104) otrzymał szereg zmian wspomagających mniejszy proces w stworzeniu wydajnego i energooszczędnego GPU.
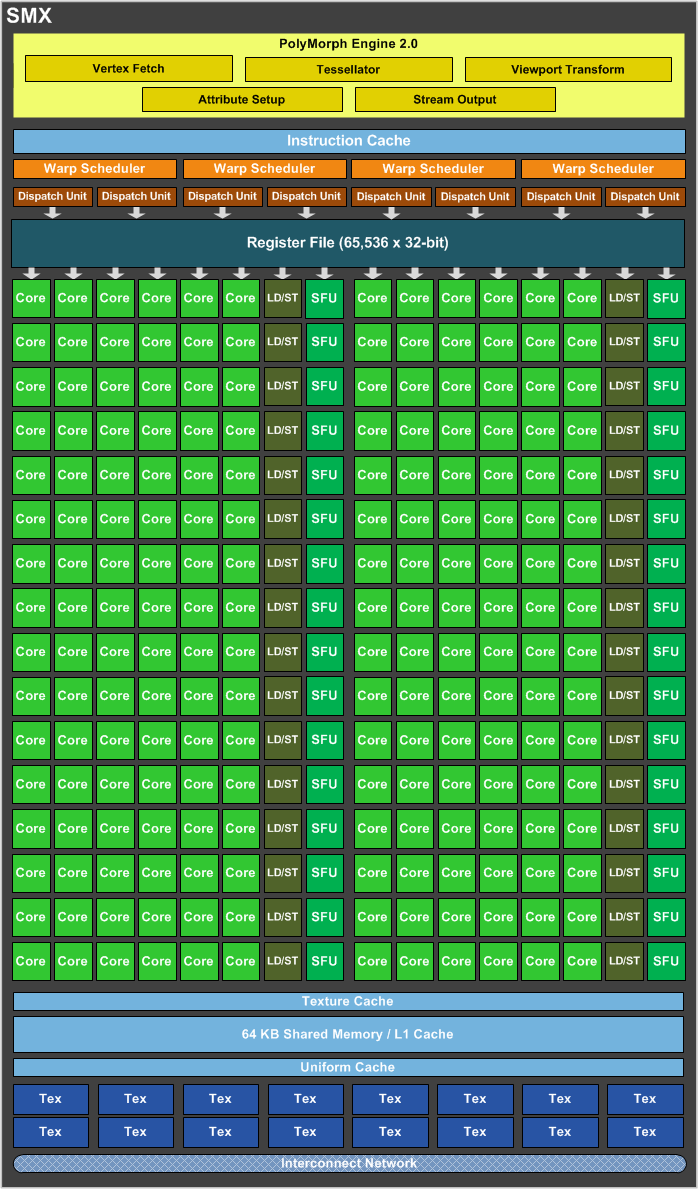

Po lewej SMX w GK104 (Kepler), po prawej SM w GF110 (Fermi)
Zmiany te zaczynają się od typowej optymalizacji pojedynczego procesora CUDA na dość innowacyjnej dla Zielonych zmianie kończąc. Ta zmiana polega na zaniechaniu taktowania shaderów dwukrotnie większym zegarem niż reszta GPU w zamian dając tychże procesorów znacznie więcej. Tak powstała nowa generacja Strumieniowego Multi-procesora, zwanego SMX. Nowy SMX otrzymał 192 rdzenie CUDA, 6-krotnie więcej niż w Fermi (GF110), a także osiem razy więcej (32) jednostek SFU (Special Function Units) odpowiedzialnych między innymi za operacje transcendentalne czy interpolacje graficzne. SMX w Keplerze otrzymało też 16 jednostek teksturujących, cztery razy więcej od SM w Fermi. Liczba silników polimorficznych pozostała bez zmian i wynosi jeden, silniki te odpowiadają przede wszystkim za teselację. Całość SMX uzupełnia dwukrotnie większa liczba jednostek odpowiedzialnych za ładowanie i zapis (32 jednostki LD/ST) oraz kolejkowanie (4 Warp Schedulery). Tak zbudowany SMX ma zapewniać dwukrotnie większą wydajność na jeden wat od SM wykorzystywanego w Fermim.
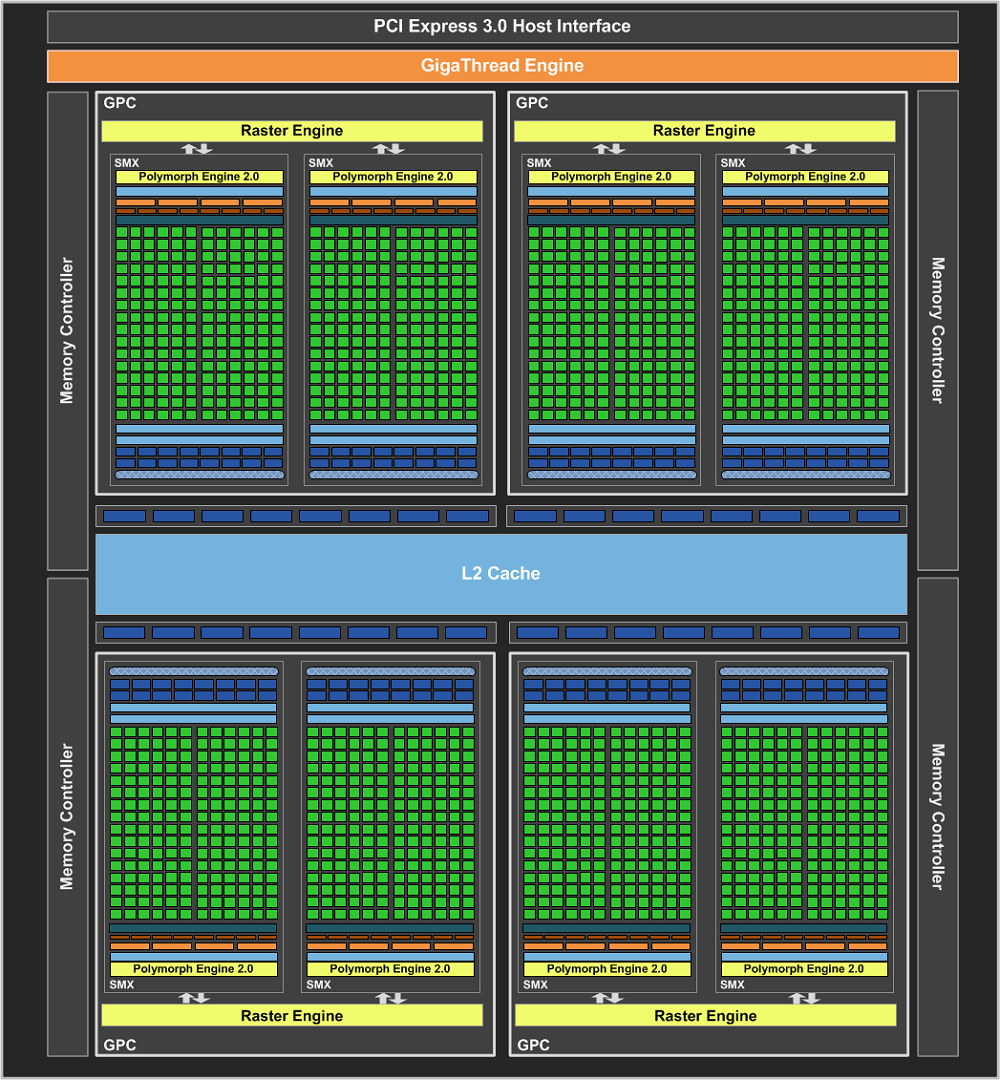
Na górze GK104 (Kepler), na dole GF110 (Fermi)
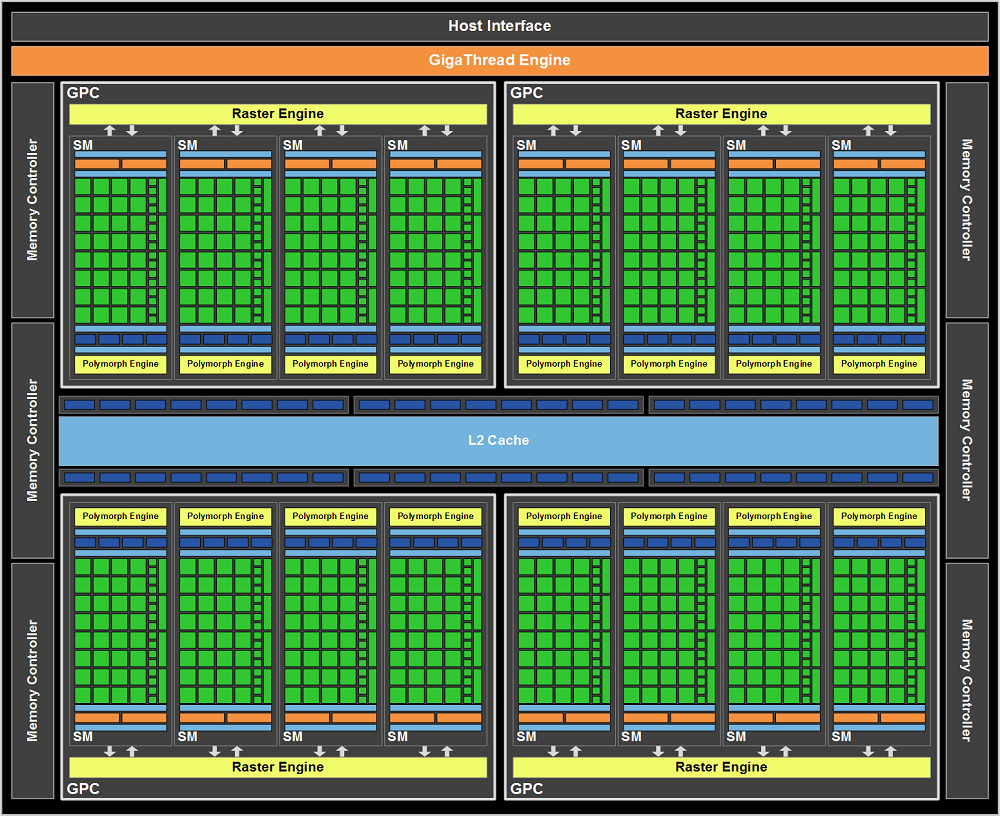
Kompletny rdzeń GeForce składa się z mieszanki klastrów precesowania graficznego GPC (Graphics Processing Clusters) i zawartych w nich multi-procesorach strumieniowych SMX, a całość uzupełniają kontrolery pamięci. Najmocniejsze GPU z nowej rodziny zawiera 4 klastry GPC, w nich po jednym dedykowanym silniku rastrowym i łącznie 8 multi-procesorów SMX. W porównaniu do 16 SM w Fermi (GF110) otrzymujemy więc 3 razy tyle procesorów CUDA, a dokładniej 1536. Otrzymujemy też 4-krotnie więcej jednostek SFU (256), 2-krotnie więcej jednostek teksturujących (128 jednostek Tex). Zachowana została liczba jednostek LD/ST (256) i jednostek kolejkujących (32). Zmalała o połowę do ośmiu liczba silników polimorficznych. W stosunku do Fermiego zmalała też liczba kontrolerów pamięci. Jest ich "tylko" cztery sztuki. Jednak dzięki daleko idącym optymalizacjom, nowe kontrolery są w stanie pracować z kośćmi GDDR5 taktowanymi zegarem aż 1502 MHz (6008 MHz efektywnie). Takie taktowanie przy łącznej szerokości szyny pamięci wynoszącej 256bit owocuje przepustowością na poziomie 192 GB/s, czyli podobnej do GTX 580. Czy nie okaże się to wąskim gardłem przekonacie się w testach. Każdy z kontrolerów pamięci sparowany jest z 128 KB pamięci podręcznej L2, i 8 ROPami (każdy ROP operuje na pojedynczej próbce koloru), co daje 512 KB pamięci L2 i 32 ROP w całym rdzeniu. Kompletne porównanie uwzględniające także różnice w zegarach między całymi rdzeniami GK104 a GF110, oraz zawartymi w nich multi-procesorami SM zawierają tabelki.
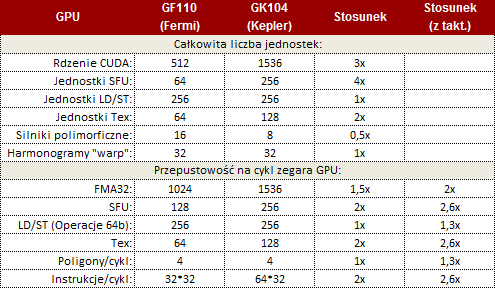
Kompletny rdzeń Keplera kontra Fermiego
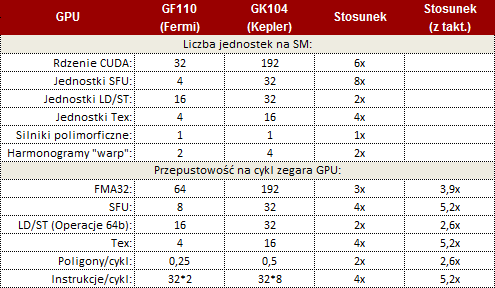
SMX Keplera kontra SM Fermiego
Koniec końców GTX 680 powinien zapewnić znaczną poprawę w wydajności cieniowania i teksturowania w stosunku do GTX 580. Zachowanie wydajności w stosunku do taktowania pozostałych aspektów na niezmienionym poziomie wciąż daje Keplerowi przewagę ze względu na znacznie wyższe standardowe taktowanie. Uważne oczy czytelnika zapewne zauważyły, że Kepler stracił jednak połowę silników polimorficznych odpowiedzialnych za teselację. Czy oznacza to gorszą wydajność nowości ze stajni Zielonych w tego typu zadaniach? Niekoniecznie. PolyMorph Engines, bo tak się nazywają po angielsku owe silniki, w GK104 oznaczone są cyferką 2. Poprawiono ich wydajność blisko dwukrotnie, a dodając do tego 30% większy zegar Keplera: GeForce GTX 680 powinien być ostatecznie szybszy od swojego poprzednika.

By wykarmić nowe znacznie mocniejsze multi-procesory SMX, zmian wymagały także jednostki odpowiedzialne za harmonogramowanie zdarzeń. W każdym SMX zawarte są 4 takie jednostki (Warp Schedulers) i każda z nich jest w stanie generować dwie instrukcje na "warp" na takt zegara ("Warp" to zestaw 32 wątków - u AMD najbliższym odpowiednikiem są "fale" wavefronts). Ponadto, pracując nad owymi jednostkami funkcje kolejkowania należało przeprojektować z nastawieniem na wydajność z wata. Zarówno Fermi jak i Kepler posiadają w strukturach jednostek harmonogramujących podobne elementy odpowiedzialne za obsługę funkcji kolejkujących. Są to: porządkowanie rejestrów dla operacji o dużym opóźnieniu, "między-warpowe" decyzje kolejkowania polegające np. na wyborze najlepszego "warpa" do obrobienia jako następnego, oraz planowanie na poziomie bloku/zestawu wątków. Na tym podobieństwa się kończą. Fermi posiada złożone, energetycznie wymagające sprzętowe bloki odpowiedzialne za zabezpieczanie by dane nie uległy uszkodzeniu: multi-portowa tablica rejestrów trzyma informacje o rejestrach niegotowych z poprawnymi danymi, oraz blok sprawdzający z pomocą owej tablicy wykorzystanie rejestrów pośród wielu w pełni zdekodowanych instrukcji "warpów", aby określić, które kwalifikują się do wydawania.
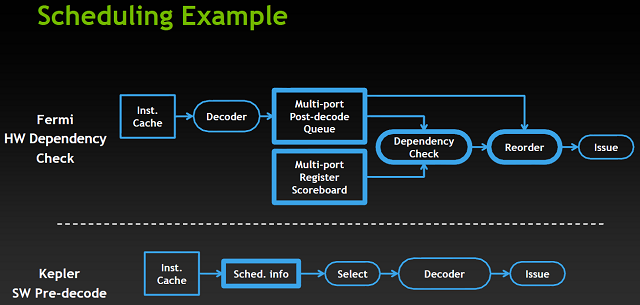
Przy projektowaniu Keplera Nvidia zdała sobie sprawę, że informacje analizowane przez te złożone bloki są deterministyczne (opóźnienia w potokach matematycznych nie są zmienne). Jest więc możliwe by kompilator określał z góry kiedy dana instrukcja będzie gotowa do wydania, ponadto udostępniając tę informację w samej instrukcji. Ten zabieg pozwolił Zielonym zastąpić skomplikowane bloki Fermiego znacznie prostszymi w Keplerze. Ten porosty blok wyciąga wstępnie zdefiniowane informacje o opóźnieniu instrukcji i wykorzystuje je przy wykreślaniu "warpów" z listy kwalifikacji (do wydania) na etapie "między-warpowego" kolejkowania.

Kolejną zmianą związaną z projektowaniem GK104 jako energooszczędnego chipu, była już wspomniana rezygnacja z dwukrotnie większego taktowania szaderów. Rozwiązanie to wprowadzone wraz z architekturą Tesli miało za zadanie zapewnić taką samą wydajność przy zmniejszeniu zapotrzebowania przestrzeni. Dwa razy szybciej taktowane bloki zapewniały taką samą wydajność, jak dwa razy więcej bloków taktowanych standardowym zegarem. Problem w tym, że zwiększenie taktowania dwukrotnie niosło za sobą blisko 4-krotne podniesienie zużycia prądu. Niższy proces technologiczny pozwolił jednak na zastosowanie większej liczby niżej taktowanych bloków mimo większego zapotrzebowania na przestrzeń.
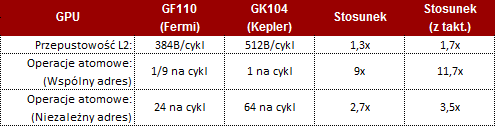
Dla wsparcia wszystkich zmian jakie zaszły w architekturze Kepler poprawiono także pamięć podręczną drugiego poziomu. Pamięć podręczna L2 współdzielona jest przez wszystkie elementy rdzenia GK104 i dla wspomagania znacznie większej wydajności pojedynczego SMX Keplera w stosunku do SM Fermiego poprawiono przepustowość tejże pamięci o 73%. Wpłynęło to znacząco na wydajność operacji atomowych, a zwłaszcza tych operujących na tym samym adresie. Pełniejsze porównanie zawiera poniższa tabela.
Nowa architektura to nie jedyna nowość wprowadzona przez NVIDIA wraz z Keplerem, bowiem „Zieloni” podobnie jak konkurencja przygotowała szereg nowinek technologicznych. Na tle poprzednich GeForców (z wyłączeniem "eksperymentów" Galaxy MDM) najbardziej innowacyjną zmianą jest poprawiony silnik odpowiedzialny za obsługę monitorów. W końcu mogliśmy pracować na więcej niż dwóch ekranach czy nareszcie zagrać w ulubione tytuły wykorzystując NVIDIA Surround jak i NVIDIA 3D Surround na trzech ekranach, a wszystko to dzięki jednej karcie graficznej. Limit ekranów obsługiwanych przez urządzenie jest odrobinę mniej imponujący niż AMD, ponieważ Kepler pozwala na pracę na "tylko" 4 ekranach.

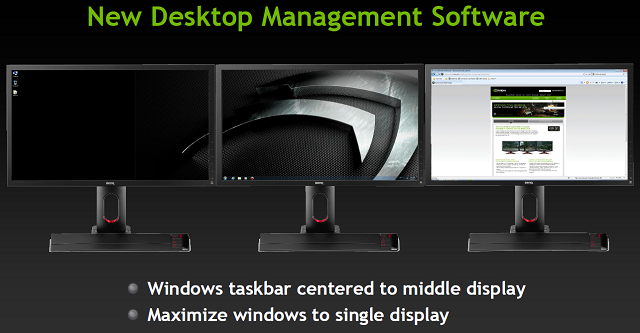
NVIDIA Surround pozwalała na grę przy 3 ekranach podłączonych do dowolnych portów - nie wymaga więc jak AMD aktywnej przejściówki DP na inny standard, czy po prostu monitora z portem DP. Możemy bez problemu uruchomić nietypową rozdzielczość 5760x1080 na trzech ekranach 1920x1200, co na Eyefinity na beta sterownikach dostarczonych na premierę HD 7970 było niemożliwe. Ponadto, na Surround pasek Windowsa domyślnie znajdował się na środkowym monitorze, a maksymalizacja aplikacji odbywała się w obrębie aktualnego monitora, a nie całego rozciągniętego wirtualnego pulpitu, w czym NVIDIA także spisała się lepiej od AMD. Dodać należy obsługę standardu wielo-strumieniowego audio i otrzymamy pełen obraz nowego silnika ekranowego.

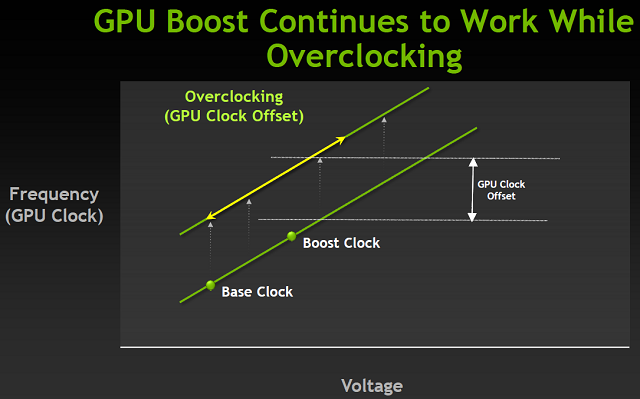
Podczas tworzenia kart graficznych, a dokładniej ustalania ich TDP, poszczególne karty sprawdza się w ciężkich warunkach termicznych pod obciążeniem obszernego zestawu realnych aplikacji 3D. W takich warunkach dobiera się ostateczne taktowania i napięcia urządzeń, tym samym ustalając ich limit TDP. Problem leży w tym, że w typowych warunkach domowych takie ciężkie środowisko nie występuje i karty bardzo rzadko zbliżają się do limitu TDP marnując tym samym ukryte weń potencjalne moce. Z pomocą przyszedł GPU Boost - nowy „przeźroczysty” dla systemu i aplikacji algorytm sprzętowo-programowy działający w tle. Jego zadaniem było i jest monitorowanie temperatury i wykorzystania rdzenia, a przede wszystkim zużycia energii. Na podstawie tych informacji GPU Boost dostosowuje napięcia oraz taktowania rdzenia.
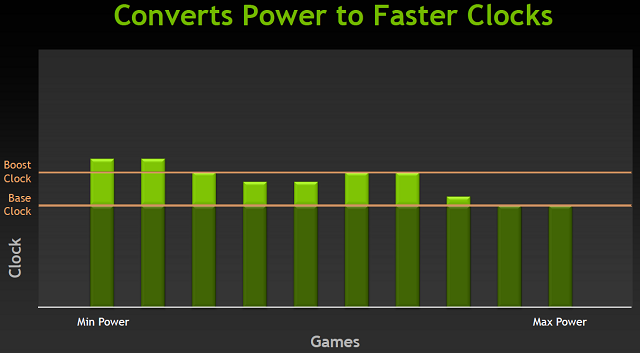
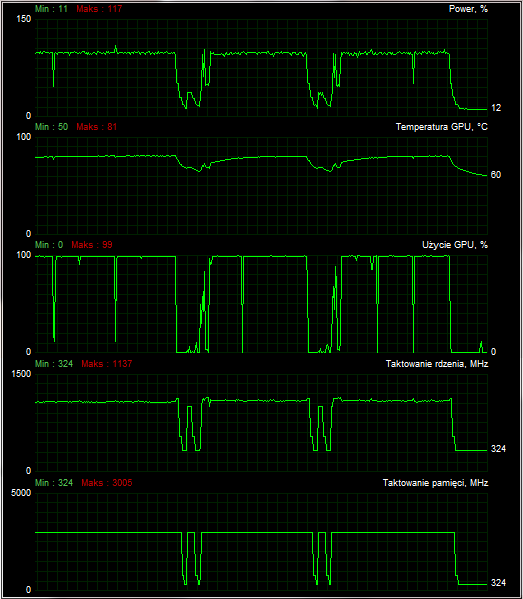
MSI Afterburner, domyślne taktowania karty, tuż po teście Crysis
Można żartować, że wprowadzenie GPU Boost przy jednoczesnym zlikwidowaniu oddzielnego dwukrotnie wyższego taktowania shaderów w stosunku do reszty rdzenia, wymusiło na NVIDII dodanie nowego "zastępczego" taktowania. Jest nim tak zwany Boost Clock podawany chociażby przez narzędzie GPU-Z. Domyślne taktowanie rdzenia (Base Clock) stanowi bazowe taktowanie karty, poniżej tego zegara karta nie powinna zejść w typowym wykorzystaniu (w GTX 680 to 1006 MHz). Wyjątkiem są aplikacje zwane wirusami konsumpcyjnymi, a takim programem jest chociażby Furmark potrafiący wycisnąć z kart więcej niż przewidują limity TDP. Natomiast nowe "boost" taktowanie przedstawiać ma średnie taktowanie z jaką karta będzie aktualnie pracować podczas obciążenia.
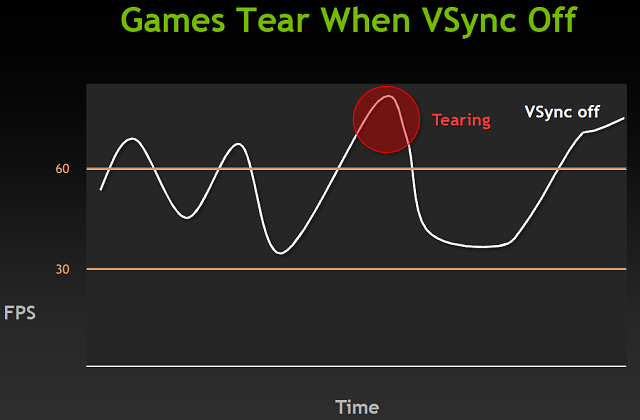
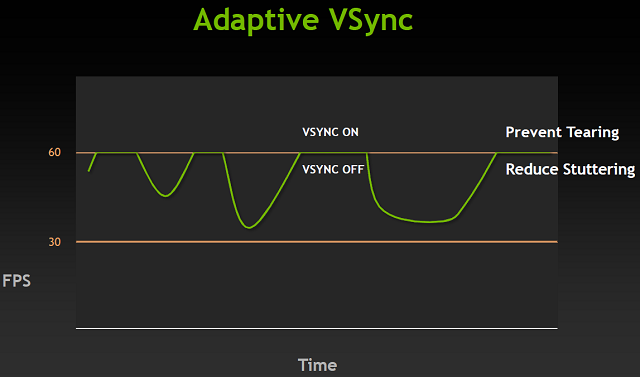
Podczas grania w gry nasza karta stara się domyślnie generować jak najwięcej klatek na sekundę. Następnie wysyła te klatki do monitora, a ten je wyświetla. Pojawia się jednak problem - monitory odświeżają obraz ze stałą predefiniowaną częstotliwością. Jeśli otrzymają dwie różne klatki w czasie odświeżania to naszym oczom ukażą się części obu tych klatek. Dokładniej górna część starszej i dolna część nowszej klatki. Powoduje to nieprzyjemny i bardzo dobrze widoczny efekt na ekranie przy szybko zmienianych scenach, zwłaszcza przy np. obracaniu widoku/kamery w poziomie. Nazywa się go Tearingiem (Poszarpaniem) - rozwiązaniem tej dolegliwości jest synchronizacja pionowa. Powoduje ona, że karta z wygenerowaniem nowej klatki czeka na monitor, a dokładniej jego proces odświeżania.
Typowy monitor LCD w 2012 roku posiadał odświeżanie pionowe z częstotliwością 60 Hz, a jeśli nasza karta graficzna jest w stanie renderować ponad 60 klatek na sekundę, to problemu nie ma - karta ogranicza generowany FPS do 60 i synchronicznie z odświeżaniem ekranu wypuszcza nowe klatki. Otrzymujemy płynny pozbawiony Tearingu obraz. Problemy zaczynają się jeśli karta nie jest w stanie generować tylu klatek. W takiej sytuacji, mechanizm synchronizacji obniży limit do jednego z dzielników maksymalnej częstotliwości odświeżania, czyli w przypadku 60Hz będzie dt 30, 20 czy np. 15Hz. Każde przejście na niższą częstotliwość jak i powrót mogą i najczęściej spowodują pojawienie się Stutteringu (Przycięć).
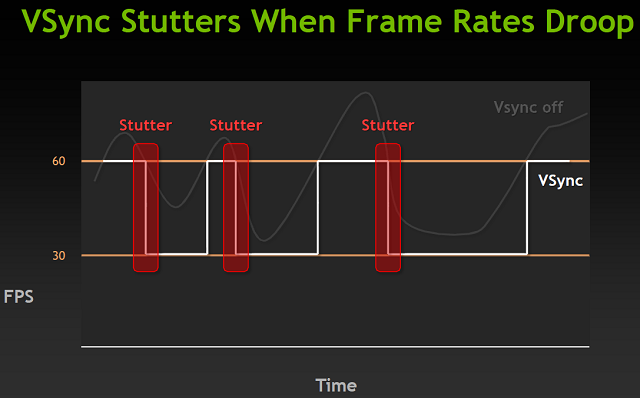
Po raz kolejny z pomocą przyszło nowe rozwiązanie NVIDII - adaptacyjna synchronizacja pionowa. W przypadku gdy nasze GPU nie było w stanie renderować wystarczająco dużej liczby klatek, aby synchronizacja działała na częstotliwości odświeżania monitora, zamiast przechodzić do dzielników zostaje po prostu wyłączona. Takie podejście do sprawy likwiduje poszarpany obraz związany z wyższym FPS niż odświeżanie, a także eliminuje przycięcia związane z przechodzeniem na niższe poziomy synchronizacji. Nie jest to jednak rozwiązanie idealne, ponieważ efekt poszarpania istnieje także w sytuacji, gdy liczba generowanych klatek jest mniejsza od częstotliwości odświeżania. Aczkolwiek efekt ten jest znacznie mniej widoczny niż oba likwidowane przez nowe rozwiązanie.
Wraz z nowymi sterownikami towarzyszącymi premierze GeForce GTX 680, NVIDIA wprowadziła także możliwość wymuszani FXAA poprzez panel kontrolny sterowników. Dotychczas jedyną możliwością korzystania z tego trybu wygładzania krawędzi, była aktywacja we wspierającej go grze, albo wykorzystanie specjalnych programów wstrzykujących stosowny kod (np. FXAA Injector). Popularność FXAA jako podstawowego trybu AA wśród deweloperów stale rośnie, ponieważ FXAA zapewniając (podobno) nawet dwukrotnie więcej FPS niż 4xMSAA, oferując zbliżony wizualnie obraz. W przeciwieństwie do MSAA, FXAA jest jednak wykorzystane na etapie post procesingu razem z blurem czy bloomem.



Porównanie trybów (Screeny Nvidii)

Wraz z Keplerem zadebiutował też nowy tryb wygładzania krawędzi. TXAA miało wykorzystywać znacznie większą wydajność nowych GeForców w dziedzinie obróbki tekstur FP16. Nowe wygładzanie było mieszanką sprzętowego AA, podejścia do AA w stylu filmów CG, oraz w przypadku trybu 2xTXAA dodatkowego opcjonalnego elementu czasowego. Znaczna część algorytmu TXAA to wysokiej jakości filtr starannie zaprojektowany z myślą o współpracy z post procesowym potokiem zgodnym z HDR. Od strony jakościowej i wykorzystania zasobów GPU, TXAA oferuje jakość porównywalną z 8xMSAA obciążając kartę jak 2xMSAA. Wyższy tryb 2xTXAA obciąża system jak 4xMSAA oferując lepszą od 8xMSAA jakość obrazu.



 Porównanie trybów (Screeny Nvidii)
Porównanie trybów (Screeny Nvidii)
Ostatnią z nowości wprowadzaną w samym rdzeniu Keplera jest sprzętowy enkoder H.264. W poprzednich generacjach kart NVIDII kodowaniem i dekodowaniem materiału wideo zajmował się programowy enkoder wykorzystujący do pracy procesory CUDA. O ile rozwiązanie takie jest znacząco szybsze niż wykorzystywanie do obliczeń CPU, to posiada ono istotną wadę - spore zużycie energii. Tak jak cała architektura Keplera, tak i NVENC podyktowany jest względami wydajności z jednego wata. Nowy sprzętowy enkoder jest blisko 4-krotnie szybszy od starszych bazujących na CUDA programowych rozwiązań, jednocześnie konsumując znacznie mniej prądu. Warto wspomnieć, że NVENC może być wykorzystywany równolegle do klasycznego programowego enkodera. Pozwala to na kodowanie dwóch materiałów na raz, jednakże algorytmy wstępnego przetwarzania NVENC mogą wymagać użycia rdzeni CUDA tym samym ograniczając ewentualnie wydajność programowego CUDA kodera.
- « pierwsza
- ‹ poprzednia
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- …
- następna ›
- ostatnia »
- SPIS TREŚCI -
- 1 - NVIDIA GeForce GTX 680 vs AMD Radeon HD 7970
- 2 - AMD Radeon HD 7970 - Budowa i parametry techniczne
- 3 - Architektura AMD Graphic Core Next
- 4 - NVIDIA GeForce GTX 680 - Budowa i parametry techniczne
- 5 - Architektura NVIDIA Kepler
- 6 - Platforma testowa i wykorzystane sterowniki
- 7 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - 3DMark Time Spy
- 8 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - Assassin's Creed: Odyssey
- 9 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - Battlefield V
- 10 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - Far Cry: New Dawn
- 11 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - GRID 2019
- 12 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - Kingdom Come: Deliverance
- 13 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - Metro Exodus
- 14 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - Shadow of the Tomb Raider
- 15 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - Witcher 3: Wild Hunt
- 16 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - Wolfenstein II
- 17 - Overclocking - maksymalne stabilne zegary
- 18 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - 3DMark Time Spy (OC)
- 19 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - Metro: Exodus (OC)
- 20 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - Witcher 3: Wild Hunt (OC)
- 21 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - Wolfenstein II (OC)
- 22 - Pobór mocy - Spoczynek i obciążenie (Battlefield V)
- 23 - Pomiar temperatur - Spoczynek i obciążenie (Wiedźmin 3)
- 24 - Pomiar głośności - Spoczynek i obciążenie (Wiedźmin 3)
- 25 - Podsumowanie - Kepler wyjechał na Tahiti

Powiązane publikacje

Test karty graficznej ASUS GeForce RTX 4070 Ti Super TUF Gaming - Jeden z najlepszych modeli niereferencyjnych
54
Test Horizon Forbidden West PC - Porównanie jakości technik skalowania NVIDIA DLSS, AMD FSR oraz Intel XeSS
34
Test wydajności kart graficznych Horizon Forbidden West PC - Ładna grafika i rozsądne wymagania sprzętowe? Niemożliwe...
156
Test karty graficznej KFA2 GeForce RTX 4070 Ti SUPER EX Gamer - Dobra wydajność, efektowne podświetlenie i podpórka w zestawie
69





