





Test AMD Radeon HD 7970 vs NVDIA GeForce GTX 680 - RetroGPU #1
- SPIS TREŚCI -
- 1 - NVIDIA GeForce GTX 680 vs AMD Radeon HD 7970
- 2 - AMD Radeon HD 7970 - Budowa i parametry techniczne
- 3 - Architektura AMD Graphic Core Next
- 4 - NVIDIA GeForce GTX 680 - Budowa i parametry techniczne
- 5 - Architektura NVIDIA Kepler
- 6 - Platforma testowa i wykorzystane sterowniki
- 7 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - 3DMark Time Spy
- 8 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - Assassin's Creed: Odyssey
- 9 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - Battlefield V
- 10 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - Far Cry: New Dawn
- 11 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - GRID 2019
- 12 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - Kingdom Come: Deliverance
- 13 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - Metro Exodus
- 14 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - Shadow of the Tomb Raider
- 15 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - Witcher 3: Wild Hunt
- 16 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - Wolfenstein II
- 17 - Overclocking - maksymalne stabilne zegary
- 18 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - 3DMark Time Spy (OC)
- 19 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - Metro: Exodus (OC)
- 20 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - Witcher 3: Wild Hunt (OC)
- 21 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - Wolfenstein II (OC)
- 22 - Pobór mocy - Spoczynek i obciążenie (Battlefield V)
- 23 - Pomiar temperatur - Spoczynek i obciążenie (Wiedźmin 3)
- 24 - Pomiar głośności - Spoczynek i obciążenie (Wiedźmin 3)
- 25 - Podsumowanie - Kepler wyjechał na Tahiti
Architektura Graphic Core Next
Opis architektury GCN będącej kręgosłupem serii HD 7900 zaczniemy od małej wycieczki w przeszłość. Wraz z pierwszym GPU zgodnym z DirectX 9, wtedy jeszcze sygnowanym logiem ATI (Radeon 9700 - R300), AMD wprowadziło projekt architektury VLIW (Very Long Instruction Word). Ponieważ operacje związane z generowaniem grafiki sprowadzały się do obliczeń wykonywanych na 4 komponentach zmiennoprzecinkowych i jednej (np. odpowiedzialnej za światło) wartości stałej - stąd nazwa VLIW5. Wraz z narodzinami Radeona HD 2900 (R600) projekt VLIW5 zachowano, bowiem wciąż spełniał on swoją rolę. Gry w większości nadal operowały z wykorzystaniem DirectX 9, czyli sprowadzały się do operacji na 5-cio elementowych wartościach.

Ulepszana architektura VLIW5 dotarła nawet do HD 5870, po czym przy badaniach nad następcą okazało się, że w typowym obciążeniu grami na każde 5 procesorów strumieniowych (SP) wykorzystywano średnio jedynie 3 lub 4. Nie był to wynik tragiczny, niemniej jednak z niewykorzystanymi SP postanowiono coś zrobić. Dodatkowo aspekt obliczeń z wykorzystaniem GPU zaczynał przybierać na sile. I tak wraz z Caymanem vel. Radeonem HD 6900 pojawił się pod strzechą nowy skurczony VLIW4, w którym z 5 SP w postaci 4 ALU (jednostka arytmetyczno-logiczna) i jednej t-jednostki odpowiedzialnej za transcendentalne operacje pozostawiono 4 ALU. T-operacje wykonywać miała teraz trójka SP. Wydajność takich skróconych SPU (Streaming Processor Unit) była z grubsza taka sama. Cały zbudowany z nich SIMD miał jednak mniej SP, dzięki czemu zyskaliśmy więcej miejsca na kolejne SIMD (Cayman miał ich 24, poprzednik Cypress 20). I tutaj tkwił główny zysk, więcej SIMD to więcej obliczeń wykonanych na raz, chociażby na liczbach zmiennoprzecinkowych podwójnej precyzji (FP64).
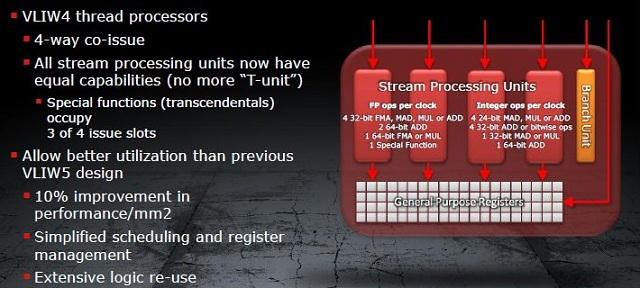
Rdzeń oparty o VLIW4 sprowadza się do gęstej sieci bardzo wielu SP oraz pamięci podręcznej, zaś kolejkowaniem zajmuje się kompilator. To on korzystając z przewagi znajomości całego programu inteligentnie przydziela zadania. Problem w tym, że kompilator nie jest w stanie analizować warunków, które wymagają wpierw uruchomienia programu i dostarczenia danych, dlatego kolejkowanie to nazywane jest statycznym. Wszystko to powoduje, że dla poprawnej pracy architektury VLIW zadania muszą się dobrze na niej mapować. Wszelkiej maści skomplikowane operacje, z którymi proste ALU nie są sobie w stanie poradzić czy instrukcje niedające się łatwo kolejkować przez zależności i konflikty, są niewskazane dla VLIW. O ile gry i zadania jakie nakładają one na GPU spełniają warunki poprawnej współpracy, to przy obliczeniach GPGPU dziwactwa VLIW zaczynają dawać się we znaki.
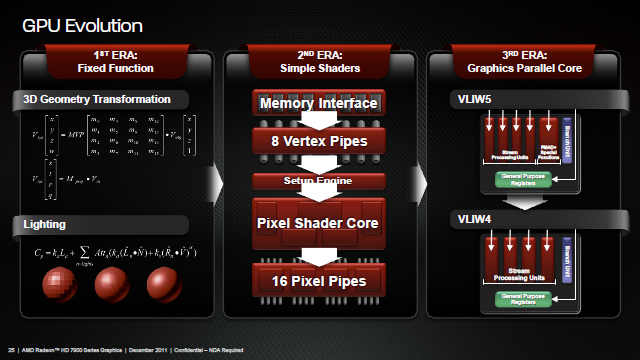
Powyższe akapity mogą rodzić pytanie: po co AMD nowa architektura skoncentrowana na wsparciu obliczeń GPGPU, skoro VLIW dobrze radzi sobie z grami i tym samym na rynku konsumenckim? Dłuższą odpowiedzią były plany AMD związane z Fusion, czyli tworzeniu GPU wspomagających CPU w obliczeniach. Krótsza odwiedź była znacznie prostsza - musieli. W 2011 roku, a dokładniej jego trzecim kwartale, rozwiązania profesjonalne Nvidii (Quadro i Tesla) osiągnęły zysk operacyjny na poziomie 95 milionów dolarów przy 230 milionach przychodów. Dla porównania część konsumencka osiągnęła 146 milionów zysków, ale przy 644 milionach przychodów. Rynek profesjonalny ma znacznie wyższy margines zysków i o ile na rynku konsumenckim AMD jest w stanie dorównać Nvidii, to jednak ci drudzy zarabiają więcej. AMD musiało wgryźć się w ten profesjonalny segment żeby się utrzymać i stąd nowa architektura.
Czym więc AMD zastąpiło VLIW? Tradycyjnym wektorowym procesorem SIMD (Single Instruction, Multiple Data). Elementy architektury GCN nie przekładają się jednak bezpośrednio na te w architekturze VLIW, toteż nie należy mylić SIMD w GCN, będącego pełnoprawnym SIMD zdolnym do pracy na wektorach 16-to elementowych, z SIMD w Caymanie będącym zlepkiem 16-tu SPU. W GCN do pojedynczego SIMD dostarcza się jedną instrukcję oraz 16 elementów danych, które przetwarzane są w ciągu jednego cyklu zegara. Podobnie jak w poprzednich architekturach również tutaj rdzeń AMD operuje na tak zwanych "falach" (wavefronts), składających się z 64 wartości/pikseli i listy instrukcji do wykonania co oznacza, że do wykonania całej fali dla jednej instrukcji potrzeba 4 cykli. SIMD zbudowane z 16-tu jednostek arytmetyczno-logicznych (ALU) tworzących wektor (Vector Unit) oraz 64KB rejestru danych (Vector Register) stanowi najmniejszy fundamentalny element nowej architektury.
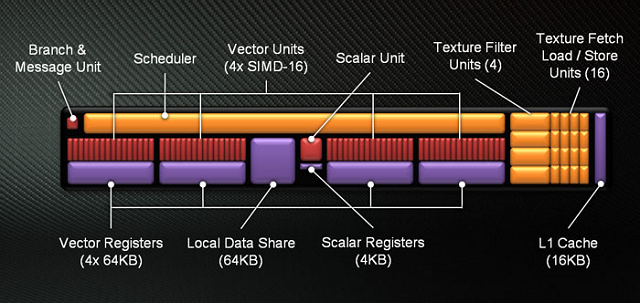
Cztery SIMD wraz z grupą elementów pomocniczych tworzą najmniejszą samodzielną jednostkę GCN. Mowa o Compute Unit (CU) - Jednostce Obliczeniowej. Lista elementów pomocniczych składa się ze sprzętowego planowania/harmonogramu (Scheduler), jednostki rozgałęziającej (Branch & Message Unit), pamięci podręcznej L1 (L1 Cache), pamięci współdzielonej (Local Data Share), czterech jednostek tekstur każdej złożonej z filtra (Texture Filter Unit) i czterech jednostek pobierania ładowania/przechowywania (Texture Fetch Load/Store Unit) oraz finalnie jednostki skalarnej (Scalar Unit) wraz z własnym rejestrem (Scalar Registers). Jednostka skalarna odpowiedzialna jest za operacje arytmetyczne których proste ALU w SIMD nie są w stanie wykonać, lub robiłyby to nieefektywnie. Takimi operacjami są np. warunki kondycyjne (if/then), czy operacje transcendentalne.
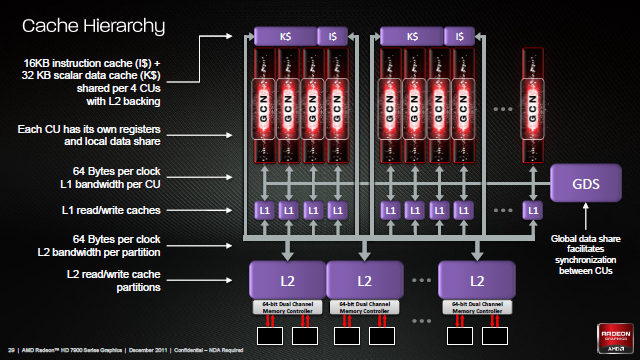
Pojedynczy CU składa się więc z czterech SIMD i jest w stanie operować na czterech różnych falach. GCN stara się więc wykonywać jedną instrukcję spośród kilku fal, co w rezultacie powoduje, że korzysta z równoważności poziomu wątków - TLP (Thread Level Parallelism) i charakter jego pracy jest spójny tzn. jego wydajność jest stabilna oraz pozbawiona skoków. Tego właśnie oczekuje się od architektury dobrej do wspomagania obliczeń. Poprzednik (Cayman) próbowałby wykonać wiele instrukcji z tej samej fali równolegle, co w przypadku jeśli instrukcje były zależne od siebie powodowało, że musiał pozwolić części swoich ALU nie robić nic. GCN w takiej sytuacji do pracy weźmie następną niezależną falę, chociażby z innego zadania. Cayman jest więc zgodny z równoważnością poziomu instrukcji - ILP (Instruction Level Parallelism) i w zależności od sytuacji jego wydajność skakała od wysokiej (brak zależności między instrukcjami - np. gry, haszowanie haseł) do niskiej (jedna instrukcja zależy od kilku pozostałych i musi być obliczana samodzielnie - np. kompresja tekstur).
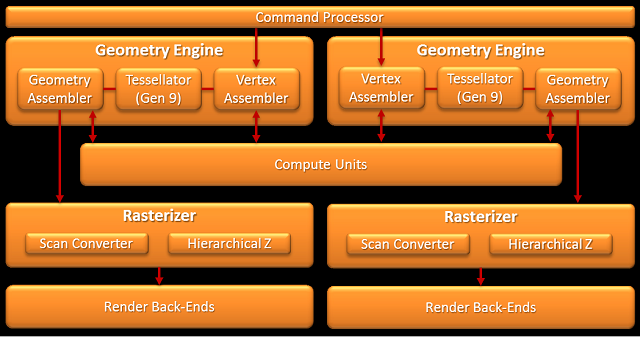
Finalny rdzeń zbudowany jest z pewnej liczby jednostek obliczeniowych (CU). W przypadku Tahiti jest to 32 CU, co daje 128 SIMD każde po 16 SP, łącznie 2048 SP w całym GPU. Oczywiście, poza samymi CU rdzeń graficzny dopełnia rzesza dodatkowych elementów. Mamy tutaj tak zwany fronend w skład którego wchodzi m.in. procesor komend (Command Processor) rozdzielający zadania do dwóch silników geometrycznych (Geometry Engine), zaś w nich nowych teselatorów 9-tej generacji, jak i dwóch silników obliczeniowych (ACE - Asynchronous Compute Engine) odpowiedzialnych za "karmienie" CU. Za CU z kolei mamy osiem końcówek renderowania, a w nich po cztery ROPy (Render Output Unit, lub bardziej poprawnie Raster Operations Pipeline) i szesnaście jednostek bufora Z/szablonowego. Jest też pamięć podręczna L2, sześć dwu-kanałowych 64-bitowych kontrolerów pamięci, oraz zestaw kontrolerów odpowiedzialnych m.in. za szynę PCI-E, wyświetlanie (Eyefinity Display Controllers), Universal Video Decoder (UDV) czy Video Codec Engine (VCE). Podobnie jak w Caymanie, każdy z silników geometrycznych jest w stanie teoretycznie wytworzyć 1 trójkąt na cykl zegara, jednak dzięki poprawkom sprawności Tahiti powinno być znacznie szybsze od Caymana.

AMD w Caymanie nie było w stanie osiągnąć teoretycznej wydajności jednostek ROP nawet w testach syntetycznych. W Tahiti dla nadążania za nowymi grami AMD musiało to poprawić. Możliwości były dwie: zwiększyć ich liczbę albo zwiększyć ich wydajność np. poprawiając podsystem pamięci. Z racji, że AMD praktycznie osiągnęło limit możliwości pamięci GDDR5, najprostszym rozwiązaniem było rozdzielenie dotychczas sparowanych z kontrolerami pamięci ROPów (jak to jest w Caymanie) i zwiększenie ilości kontrolerów, a co za tym szerokości całkowitej szyny i jej przepustowości. I tak Tahiti otrzymało 8 bloków renderowania z ROPami i 6 odseparowanych od nich kontrolerów pamięci, dzięki czemu w testach wypełniania pikseli jest ponad 50% wydajniejszy od starszego brata HD 6970. Oczywiście rozdzielenie ROPów i kontrolerów musiało pociągnąć za sobą jakieś negatywne aspekty jak chociażby potencjalnie wyższy czas dostępu, ale ich wpływu nie znamy, natomiast dwa dodatkowe kontrolery zaowocowały także o 50% większą pamięcią cache L2 z racji, że z każdym kontrolerem sparowane jest 128KB tejże pamięci podręcznej. Koniec końców jeśli AMD odrobiło pracę domową, GCN powinno charakteryzować się znacznie wyższą wydajnością obliczeniową GPGPU, jednocześnie zachowując wydajność w grach w stosunku do architektury VLIW4 (dla podobnej liczby SP). Właściwe rozłożenie wykonywania operacji cieniowania w grach na CU w GCN jest zupełnie inne niż na SPU w VLIW, ale prędkość powinna być podobna. Dodatkowo gry wykorzystujące DirectCompute powinny zyskać dzięki poprawionej wydajności GPGPU.
Jedną z nowości w Windows 8 wchodzącym w październiku 2012 roku do sprzedaży, była następna wersja popularnego API Direct3D sygnowana tym razem numerkiem 11.1. Najlepszym podsumowaniem nowego wydania było określenie "odcinania kuponów", bowiem o ile Microsoft wprowadzi kilka nowych funkcji, to w porównaniu nawet do wydania 10.1 czy chociażby 9.0c kolejna odsłona D3D okazała się dość nieznacznym ulepszeniem istniejącego API (Application Programming Interface), niż zbiorem nowych instrukcji. Analizując jednak wsteczną kompatybilność DirectX 11.1 odnajdziemy jedną nową funkcję wymagającą nowego sprzętu ją wspierającego: Target Independent Rasterization - Rasteryzacja niezależna od celu. W rezultacie istniejące karty AMD zgodne z DirectX 11 nie są w pełni kompatybilne z nowym 11.1, co naprawiło oczywiście Tahiti, jednocześnie będąc pierwszym GPU wpierającym DirectX 11.1. W praktyce oznaczało to tyle, że kolejny raz sprzęt wyprzedził oprogramowanie.

Co takiego zyskali użytkownicy? Największymi zmianami były formalizacja wsparcia dla Stereo 3D oraz WDDM 1.2, które jako takie zostało w Windows 8 równolegle wprowadzone wraz z nowym D3D. Formalizacja Stereo 3D pozwoliła grom natywnie wspierającym tryby S3D na robienie tego z wykorzystaniem Direct3D, co z kolei wpłynęło na ujednolicenie rynku S3D. Inaczej mówiąc, gry wspierające S3D pracowała tak samo bez względu na to jaki sprzęt posiadamy, tak długo jak wspiera on S3D. Tytuły pozbawione natywnego wsparcia wciąż będą wymagały pomocy oprogramowania pośredniczącego (middleware). WDDM 1.2 było z kolei kolejnym krokiem Microsoftu w celu zbliżenia traktowania GPU do sposobów w jakie traktuje się CPU - między innymi usprawniono znany z Windows 7 mechanizm TDR odpowiedzialny za resetowanie GPU. W Windows 8 z WDDM 1.2 GPU było podzielone na pomniejsze "silniki" umożliwiające resetowanie, tym sposobem w przypadku gdy np.: przeglądarka wywinie nam orła resetowaniu ulegnie tylko "silnik" za nią odpowiedzialny, nie a pozostałe np.: zajmujące się grą.

Id Software może nie jest już wielką stajnią tworzącą najpopularniejsze silniki do gier, jaką była za czasów Quake III: Arena, wciąż jednak ich technologia nosi znamiona rewolucyjnej. Silnik id Tech 4 wprowadził technologie Shadow Volume, później zaimplementowaną po raz pierwszy sprzętowo przez Nvidię jako UltraShadow, aktualnie wykorzystywaną w różnych formach w większości GPU. Silnik id Tech 5 zaprezentował z kolei technologię Megatexture, którą AMD zaimplementowało sprzętowo jako pierwsze, właśnie pod przydomkiem Partially Resident Textures (PRT) - częściowo obecnych tekstur. Idea schowana za PRT/Megatexture jest prosta: zamiast traktować tekstury jako pojedyncze obiekty, powinniśmy je dzielić na mniejsze "płytki", dzięki czemu jeśli potrzebujemy tylko jej fragmentu, możemy załadować kilka "płytek" i resztę pominąć lub załadować w niższej jakości. Generalnie technologia poprawia strumieniowanie tekstur, poprzez użycie kawałków zamiast całych tekstur, likwidując transfer zbędnych danych. Dodatkowo pozwoliła na tworzenie gier wykorzystujących wyższej jakości tekstury, przy zachowaniu obciążenia zasobów odpowiadającym grom pozbawionym PRT.
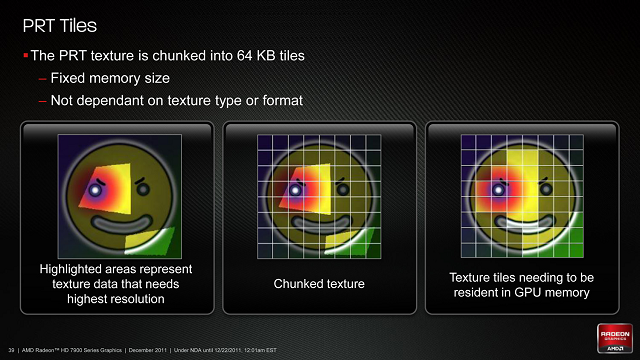
Aby technologię PRT zaimplementować sprzętowo, AMD musiał obsłużyć dwie rzeczy: konwersję tekstur i zarządzanie nimi. Konwersja w przypadku AMD sprowadzą się do wczytywania i dzielenia tekstur na części. Rozmiar "płytek" będzie stały: 64KB, co przy niekompresowanych teksturach o głębi 32-bit wystarczy dla kawałków o rozmiarze 128 x 128 pikseli. Aspekt pamięci czyli zarządzanie owymi "kaflami", powoduje że lokalna pamięć wideo zamienia się w swoisty wielki bank pamięci podręcznej, w której cząstki tekstur są mapowane/przypinane w razie potrzeby, a następnie "wysiedlane" zgodnie z zasadami pamięci podręcznych. Ponadto, sprzętowo obsługuje się konwersję/translację stron/płytek jeśli potrzebnej brak jest w cache.
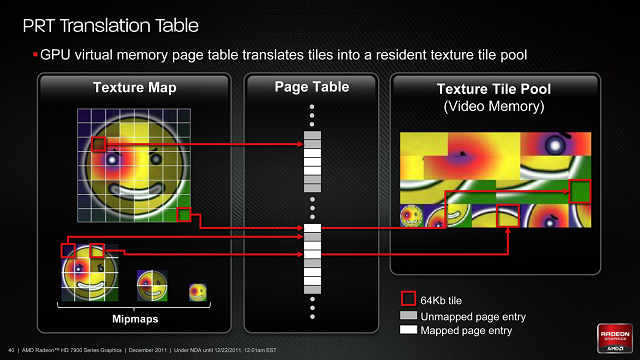
AMD korzystając z technologii Disneya zwanej Per-Face Texture Mapping (PTEX) stworzyło demo pokazujące możliwości PRT. PTEX to technika mapowania tekstur na poligony w stosunku 1 do 1, z której Disney korzysta przy produkcji-renderowaniu, ponieważ ograniczenie tekstur do pojedynczych wielokątów likwiduje problemy i złożoności związane z mapowaniem tekstury na wiele poligonów jednocześnie. Demo nie tylko zyskuje z PTEX z powodów dla których używa tej technologii Disney, ale również dlatego, że w połączeniu z teselacją bardzo upraszcza to obliczanie wektorów przesunięć, a tym samym generowanie grafiki w grach bogatych w teselację. No i oczywiście samo PRT poprawia efektywność dostępu do "płytek" tekstur PTEX. Jedyną wadą PRT jest silna restrykcyjność Direct3D w stosunku do niestandardowych funkcji i na chwilę obecną można z PRT korzystać jedynie przy pomocy innych API jak OpenGL (Megatekstury Carmaca korzystają z OpenGL 3.2). Powoduje to, że o ile PRT ma wsparcie sprzętowe, to wsparcie oprogramowania jest ograniczone.
- « pierwsza
- ‹ poprzednia
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- …
- następna ›
- ostatnia »
- SPIS TREŚCI -
- 1 - NVIDIA GeForce GTX 680 vs AMD Radeon HD 7970
- 2 - AMD Radeon HD 7970 - Budowa i parametry techniczne
- 3 - Architektura AMD Graphic Core Next
- 4 - NVIDIA GeForce GTX 680 - Budowa i parametry techniczne
- 5 - Architektura NVIDIA Kepler
- 6 - Platforma testowa i wykorzystane sterowniki
- 7 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - 3DMark Time Spy
- 8 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - Assassin's Creed: Odyssey
- 9 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - Battlefield V
- 10 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - Far Cry: New Dawn
- 11 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - GRID 2019
- 12 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - Kingdom Come: Deliverance
- 13 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - Metro Exodus
- 14 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - Shadow of the Tomb Raider
- 15 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - Witcher 3: Wild Hunt
- 16 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - Wolfenstein II
- 17 - Overclocking - maksymalne stabilne zegary
- 18 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - 3DMark Time Spy (OC)
- 19 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - Metro: Exodus (OC)
- 20 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - Witcher 3: Wild Hunt (OC)
- 21 - Test wydajności GeForce GTX 680 vs Radeon HD 7970 - Wolfenstein II (OC)
- 22 - Pobór mocy - Spoczynek i obciążenie (Battlefield V)
- 23 - Pomiar temperatur - Spoczynek i obciążenie (Wiedźmin 3)
- 24 - Pomiar głośności - Spoczynek i obciążenie (Wiedźmin 3)
- 25 - Podsumowanie - Kepler wyjechał na Tahiti

Powiązane publikacje

Test karty graficznej ASUS GeForce RTX 4070 Ti Super TUF Gaming - Jeden z najlepszych modeli niereferencyjnych
54
Test Horizon Forbidden West PC - Porównanie jakości technik skalowania NVIDIA DLSS, AMD FSR oraz Intel XeSS
34
Test wydajności kart graficznych Horizon Forbidden West PC - Ładna grafika i rozsądne wymagania sprzętowe? Niemożliwe...
156
Test karty graficznej KFA2 GeForce RTX 4070 Ti SUPER EX Gamer - Dobra wydajność, efektowne podświetlenie i podpórka w zestawie
69





